I’ve heard of continuity management, previously called crisis management, used in business and I think government institutions. There are international conferences with experts on the subject. Risk assessment is a big part of it, systematically listing all imaginable risks, planning how to recover or adapt in those scenarios. They probably assume plans are always incomplete, so prepare for surprises and unknown-unknown’s. To have a plan for what to do when the unexpected happens and all other plans fail. Oh there’s even ISO standards for it:
In the introduction to systems thinking, I noticed the phrase “leverage points” of a system. Those sound like risks, critical points that the system relies on for its stability, where a small change can have large effects. So managing risk is about reducing uncertainty in an inherently chaotic system and environment.
A curious wording I saw that I’ve been thinking about, how “surprises” are related to entropy and the amount of information in a signal.
Surprisal is a measure of the amount of information gained from an event, defined mathematically as the negative logarithm of the probability of that event occurring. It quantifies how surprising an event is, with rarer events yielding higher surprisal values.
In information theory, the information content, self-information, surprisal, or Shannon information is a basic quantity derived from the probability of a particular event occurring from a random variable. The Shannon information can be interpreted as quantifying the level of “surprise” of a particular outcome. As it is such a basic quantity, it also appears in several other settings, such as the length of a message needed to transmit the event given an optimal source coding of the random variable.
The Shannon information is closely related to entropy, which is the expected value of the self-information of a random variable, quantifying how surprising the random variable is “on average”.
The word “surprise” seems anthropomorphized, like it gives it a subjective dimension. Maybe that’s intentional, because it assumes a recipient of information, a subject and observer who experiences and interprets the signal into meaning. Or it’s just another way of describing probability, from “totally expected” to “wow didn’t see that coming at all”.
I think it was in relation to Stage X, I heard of the concept of software supply-chain integrity and continuity of infrastructure.
57 billion requests in Q4 of 2025 for package dependencies from vendors, in order of requests:
- Maven, npm, Docker, YUM, PyPI, Helm, Nuget, Debian, Conan, Gradle, RubyGems, Go, OCI, Cargo, Sbt, Helm, Ivy, Composer, Terraform, Opkg, Conda, P2, Pub, Swift, Alpine, Cocoapods, Cran, VCS, Chef, Vagrant, Terraform, Bower, Ansible, Puppet, Hugging Face
In 2024, security researchers around the world disclosed nearly 33,000 new CVEs (Common Vulnerabilities and Exposures), a 27% increase from the previous year, surpassing the growth rate of packages (24.5% YoY).
Most common types of vulnerabilities
- Improper Neutralization of Input During Web Page Generation
- Out-of-bounds Write
- Improper Neutralization of Special Elements used in an SQL Command
- Out-of-bounds Read
- Use After Free
- Improper Limitation of a Pathname to a Restricted Directory
- Improper Neutralization of Special Elements used in an OS Command
- Cross-Site Request Forgery
- Buffer Copy without Checking Size of Input
- NULL Pointer Dereference
- Unrestricted Upload of File with Dangerous Type
- Improper Authentication
- Concurrent Execution using Shared Resource with Improper Synchronization (‘Race Condition’)
- Improper Locking
- Improper Neutralization of Special Elements used in a Command
- Incorrect Authorization
- Missing Authorization
- Integer Overflow or Wraparound
- Improper Input Validation
- Improper Restriction of Operations within the Bounds of a Memory Buffer
- Uncontrolled Resource Consumption
How Organizations are Applying Security Efforts Today
- Sourcing restrictions
- Scanning
- Establishing visibility and control across application pipelines
Organizations need to control, or at least have strong visibility into what is coming into their software supply chain via their developers and the dependencies referenced in their applications. Over 71% of organizations allowing developers to download directly from the internet is concerning, and a major violation of software supply chain security best practices. An artifact management solution to proxy public registries should be in place at every organization.
By the time you’re having to establish a proxy package manager to filter and verify the endless stream of software written by other people running on your machines.. That doesn’t sound secure at all - like the “hero of Haarlem”, the Dutch boy Hans Brinker who saves his village by sticking a finger in a leaking dam.

The report shows a concerning state of affairs with modern software and computing supply chain, systemically vulnerable and insecure, with only exceptional islands of verified safety.
What’s not mentioned is the bottom-up approach of thinking very small, starting again from scratch, to rethink and rebuild everything from first principles and primitives. As Richard Feynman said, There’s Plenty of Room at the Bottom. It seems to me that’s the surest way to verify an entire system part by part, down to the bottom. But maybe that’s not practical for most business situations where there’s already an existing pile of running code of unbounded complexity.

There’s a site infinitemac.org, where you can run emulators of classic Macintosh and NeXTStep. Tim Berners-Lee wrote WorldWideWeb.App on this version, running on the NeXTcube pictured above.
It’s based on a WebAssembly port of the NeXT emulator called Previous.
At a glance, the code is typical of emulators and virtual machines: time, signal, CPU, memory, I/O, audio, video, SDL.. Ah, I’m looking in the wrong place, the object-oriented magic of NeXT, if there is such a thing, would be on the software side. How the operating system and applications are organized and communicate with each other.
But I’m guessing those are binary blobs without source code. Then it’s worthless post-collapse, the system is not bootstrappable, it cannot “create its own parts” to build new instances of itself. Bootstrappability is a strict requirement to meet, it’s merciless in filtering out over-engineered software, that includes a majority of commercial systems and large language models too. If we can’t make it ourselves, it’s a risk of external dependency.
With NeXT, and general interest in retro machines, I think what’s valuable is not only the specific hardware/software implementations, but the conceptual design, how it makes you imagine a new horizon of what computers can be, a higher order integration of art and science, aesthetics and technology. Function and form, practical and beautiful. Like Macintosh System 7 is an eternal nostalgia, a historical fantasy and imaginary past, a childhood wonder at the magic of computers. And what is history but what we imagine it to be? At least for me I’m motivated to study these software artifacts not for its own sake, but to consume and digest the best ideas for the purpose of making it mine, and creating new things out of the rich ground.
NeXT + OOP + WWW + HTML = ?
Next-generation networked objects and hypermedia programming language.
A play on words worthy of wooing Silicon Valley venture capitalists - or is there something real in this vortextual nexus of conceptual pearls. What would such a chimera look like.
I have a mutant language project incubating for a while, for which malleable systems research is relevant. It started as a mathematical expression evaluator that grew into a small language of infix notation, a superset of JSON, familiar and easy to learn - but that’s not the important or interesting part. The curious thing was that the code parsed into an abstract syntax tree that ran on a Lisp machine/interpreter, with macros and tail-call elimination. This latter I wrote inspired by mal, the Make-A-Lisp project.
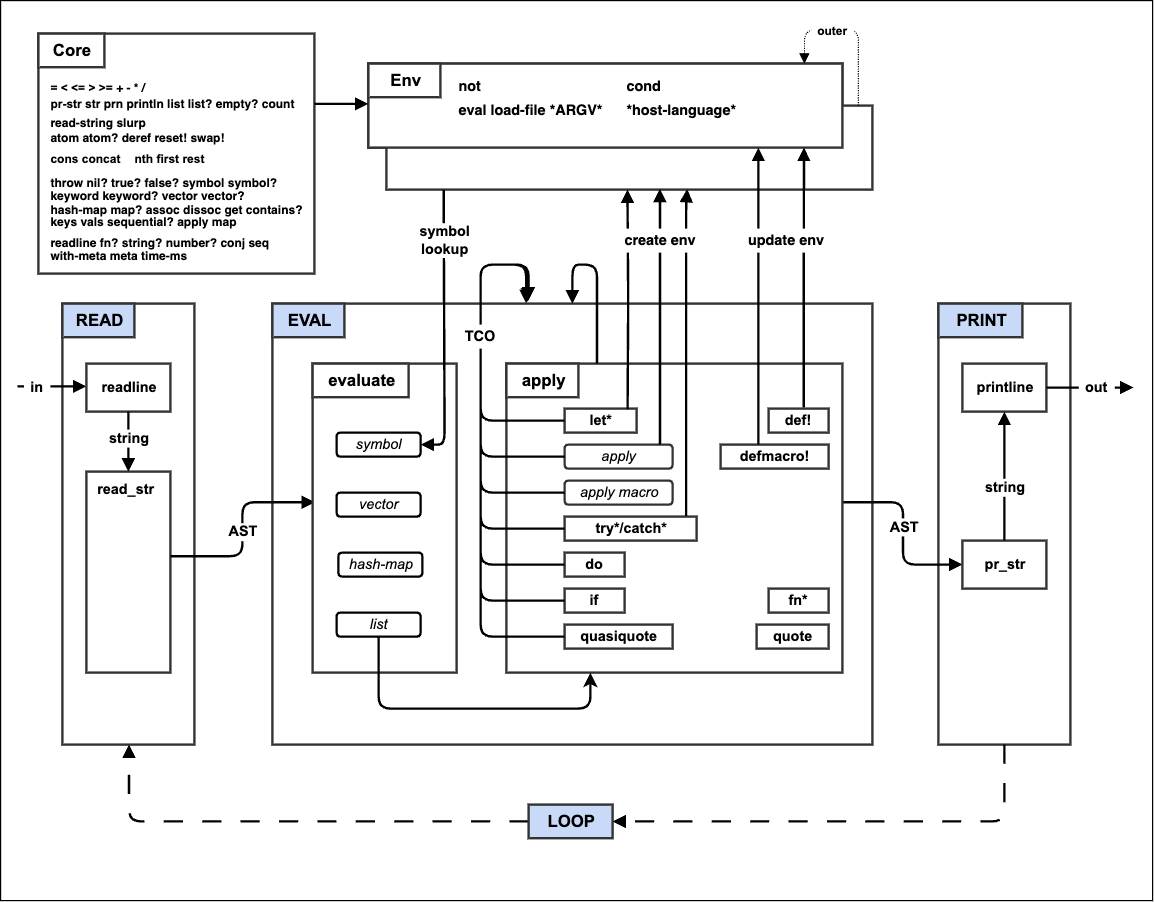
It’s a Lisp implemented in 89 languages:
- Ada, Ada.2, BASIC (C64 and QBasic), BBC BASIC V, Bash 4, C, C#, C++, C.2, ChucK, Clojure, CoffeeScript, Common Lisp, Crystal, D, Dart, ES6 (ECMAScript 2015), Elixir, Elm, Emacs Lisp, Erlang, F#, Factor, Fantom, Fennel, Forth, Functional tests, GNU Guile 2.1+, GNU Make 3.81, GNU Smalltalk, GNU awk, Generating language statistics, Go, Groovy, Hare, Haskell, Haxe (Neko, Python, C++ and JavaScript), HolyC, Hy, Io, Janet, Java 1.7, Java, using Truffle for GraalVM, JavaScript/Node, Julia, Kotlin, LaTeX3, LiveScript, Logo, Lua, MATLAB (GNU Octave and MATLAB), Mal, NASM, Nim 1.0.4, OCaml 4.01.0, Object Pascal, Objective C, PHP 5.3, PL/SQL (Oracle SQL Procedural Language), PL/pgSQL (PostgreSQL SQL Procedural Language), Performance tests, Perl 5, Perl 6, Picolisp, Pike, PostScript Level 2/3, PowerShell, Prolog, PureScript, Python2, Python3, Q, R, RPython, Racket (5.3), Rexx, Ruby #2, Ruby (1.9+), Rust, Rust (1.38+), Scala, Scheme (R7RS), Self-hosted functional tests, Skew, Standard ML (Poly/ML, MLton, Moscow ML), Starting the REPL, Swift 2, Swift 3, Swift 4, Swift 5, Tcl 8.6, TypeScript, VHDL, Vala, Vimscript, Visual Basic Script, Visual Basic .NET, WebAssembly (wasm), Wren, XSLT, Yorick, Zig, jq, miniMAL.
The Make-A-Lisp Process
- Step 0: The REPL
- Step 1: Read and Print
- Step 2: Eval
- Step 3: Environments
- Step 4: If Fn Do
- Step 5: Tail call optimization
- Step 6: Files, Mutation, and Evil
- Step 7: Quoting
- Step 8: Macros
- Step 9: Try
- Step A: Metadata, Self-hosting and Interop
This cross-platform kernel and abstract machine is what interests me. It can be a compile target for any prefix/postfix/infix-notation language, that can be parsed and converted to the same Lisp-y machine instructions. The project has ten thousand stars, so people do appreciate its educational value. But I feel like there’s untapped practical potential for a simple language that can be implemented in so many languages. Like a primitive organism that requires very few elements to survive, I’d imagine such a language would have great post-collapse utility and adaptability.
The same I feel about elvm (EsoLangVM Compiler Infrastructure), a minimal C compiler implemented in, or converted to, dozens of backends including a Turing machine in the game of life. As long as one of the backends survives the downfall of civilization, programs written in Universal Lisp or Forever C99 can be revived to the warmth of our descendants.
My utopian hypermedia language, whose latest name is Expreva (“expression evaluator”), has gone through rough sketches and prior generations of imperfect forms, including actually shipped products with thousands of users, from a library of shortcodes to extensible HTML template language with loops and logic, as well as intermediary experiments with names like Bonsai (tree editor) and Eleme (reactive stateful elements). It might be too ambitious what I’m trying to go for, but I’ve thought about it for years from different angles.
It involves an integrated development environment, structural editing, interactively explorable interface, and live view of running code/templates. A language that unifies document structure, design/styling, interactivity/scripting - as if reinventing HTML/CSS/JS/Wasm in a coherent design with the benefit of hindsight. And somehow all written from scratch in a cross-platform way, C99 and/or self-hosted Lisp-to-Wasm compiler, that can build binary executables for a wide range of targets, virtual and real machines.
Well, the proof is in the pudding - make it work, make it right, make it fast. “I’ll be your Xanadu, will you be my Shangri-La.” (© 2026 for my next album)
There’s the computational hypermedia I dream of, and the reality of prima materia I’m working with. A related practical project is using Electron/Chromium or other webview library to open tiled transparent windows on my desktop environment, that lets me use web technology to build bidirectional interactions with the backend via WebSockets. The tech stack is not ideal, but it’s the quickest route to achieve what I want - I’m exploring text/terminal-based interface in parallel. So far I’m building my own file manager and media player, because I’m not satisfied with any of the open source solutions. I’m hoping some components will be useful for web applications with local storage or remote servers. I wish I could write in the same language a dynamic HTML-based app that runs in the web browser or interact with in the terminal.
In the back of my mind I’m often on the look-out for common threads that tie together or reveal relationships among the myriad of concepts I’m interested in. A code editor is such an inter-conceptual nexus, particularly how it handles many programming languages in a unified way. I’ve worked with CodeMirror fairly deeply, and would like to develop more sophisticated editor features that integrate with the language, like interacting with values, suggesting keywords or snippets, documentation on hover, inline examples; a tree view interface to visually build a program synced to code view; always pretty format code on every key, so there’s no need to manually indent.
A web-based code editor would be useful for any language, as a friendly playground to explore it without having to install anything. Examples of what I’ve experimented with:
- HTML template editor with live view on every change
- C editor that compiles the code to Wasm and runs it on every keypress
- Lisp editor with live view of parsed nodes and evaluated result
I can extrapolate to:
- Lua editor for making LÖVE games in the browser
- Lua/YueScript for Cardumem, Pharo (?) for HyperDoc
- Uxn editor with canvas.. I checked, it already exists: learn-uxn
With CodeMirror, the editor is specific to the implementation so I can’t reuse its data structure or logic in other contexts, for example, if I want a minimal terminal code editor for my Lisp variant written in C - or a REPL with syntax highlight, as a single- or multi-line editor in the terminal. I’ve been reading the source code and studying:
jart/bestline- Bestline: Library for interactive pseudoteletypewriter command sessions using ANSI Standard X3.64 control sequences. Fork oflinenoise, a minimal reimplementation ofreadline, by antirez, the creator of Redis.kilo- A text editor in less than 1k lines of C, also by antirez. The tutorial Build Your Own Text Editor extends it further as a learning exercise.micro- a modern and intuitive terminal-based text editor (written in Go)fresh- a terminal editor built for discoverability (Rust)
This last one is pretty nice, the TUI (textual user interface) reminds me of the editor environment for Turbo Pascal.
The terminal interface will likely survive and thrive in the post-apocalyptic computing environment, with constrained resources of CPU, memory, networking if any. Plain text in ASCII may rule the earth again.
Of loops and vortices..
In the tale, a man recounts how he survived a shipwreck and a whirlpool. It has been grouped with Poe’s tales of ratiocination and also labeled an early form of science fiction.
Where have I seen that word..
The calculus ratiocinator is a theoretical universal logical calculation framework, a concept described in the writings of Gottfried Leibniz, usually paired with his more frequently mentioned characteristica universalis, a universal conceptual language.
It’s so charming and poetic how these philosophers dared to dream so far.
Leibniz intended his characteristica universalis or “universal character” to be a form of pasigraphy, or ideographic language. This was to be based on a rationalised version of the ‘principles’ of Chinese characters, as Europeans understood these characters in the seventeenth century. From this perspective it is common to find the characteristica universalis associated with contemporary universal language projects like Esperanto, auxiliary languages like Interlingua, and formal logic projects like Frege’s Begriffsschrift.
Leibniz said that his goal was an alphabet of human thought, a universal symbolic language (characteristic) for science, mathematics, and metaphysics.
In May 1676, he once again identified the universal language with the characteristic and dreamed of a language that would also be a calculus—a sort of algebra of thought.
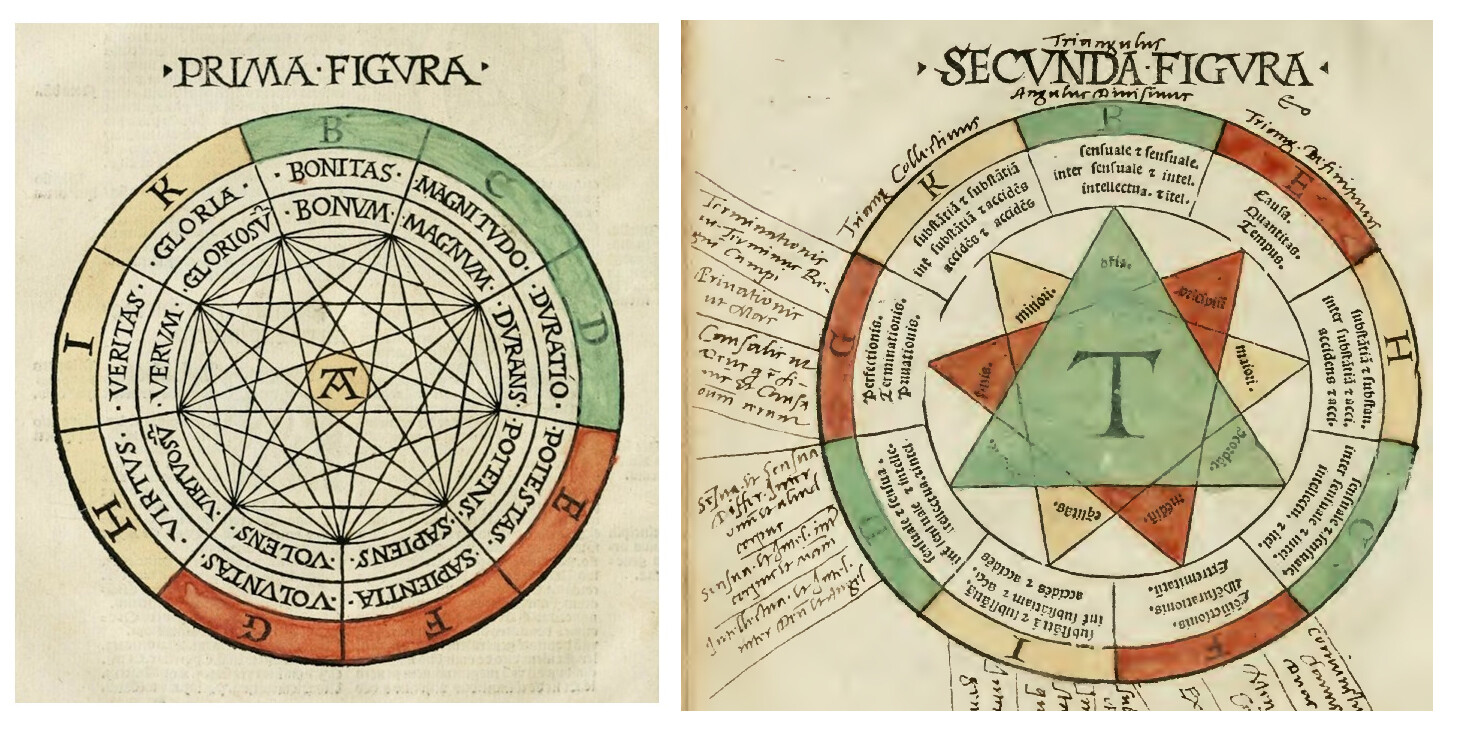
Leibniz gave Egyptian and Chinese hieroglyphics and chemical signs as examples of real characteristics writing. He even includes among the types of signs musical notes and astronomical signs (the signs of the zodiac and those of the planets, including the sun and the moon). It should be noted that Leibniz sometimes employs planetary signs in place of letters in his algebraic calculations.
Leibniz acknowledged the work of Ramon Llull, particularly the Ars generalis ultima (1305), as one of the inspirations for this idea. The basic elements of his characteristica would be pictographic characters unambiguously representing a limited number of elementary concepts. Leibniz called the inventory of these concepts “the alphabet of human thought.”
I see what you mean, Doktor Leibniz speaking through the centuries, we’re working on it.
In modern terminology, Leibniz’s alphabet was a proposal for an automated theorem prover or ontology classification reasoner written centuries before the technology to implement them.