Wondering: is anyone in CS working on languages less powerful than code? Where I interpret “code” as “Turing-complete language”? There’s the well-known hierarchy of automata theory, but is there anything else? In particular something that explicitly trades Turing-completeness for some other desirable characteristic?
There must be lots of DSLs that are not quite or only accidentally Turing-complete. What I am interested is something more abstract. Principles for making such languages rather than ad-hoc designs.
Dhall is a language that is explicitly not Turing-complete. Dhall is something like a DSL in that it can strictly generate configuration for permissive consumers. Working without loops, comparisons, or recursive types can be confusing but fun in a perverse way.
Thanks a lot for your welcome. I have been an old timer, but not as active as I would like, because, as you said, the content here is pretty addictive (thanks also for the link, BTW)… Now I’m catching with the community slowly, at manageable peace.
Mathematical expression evaluators come to mind, that are often used to (more or less) safely run user-submitted code. Query languages like SQL and GraphQL too, where the expressions perform a subset of allowed computation.
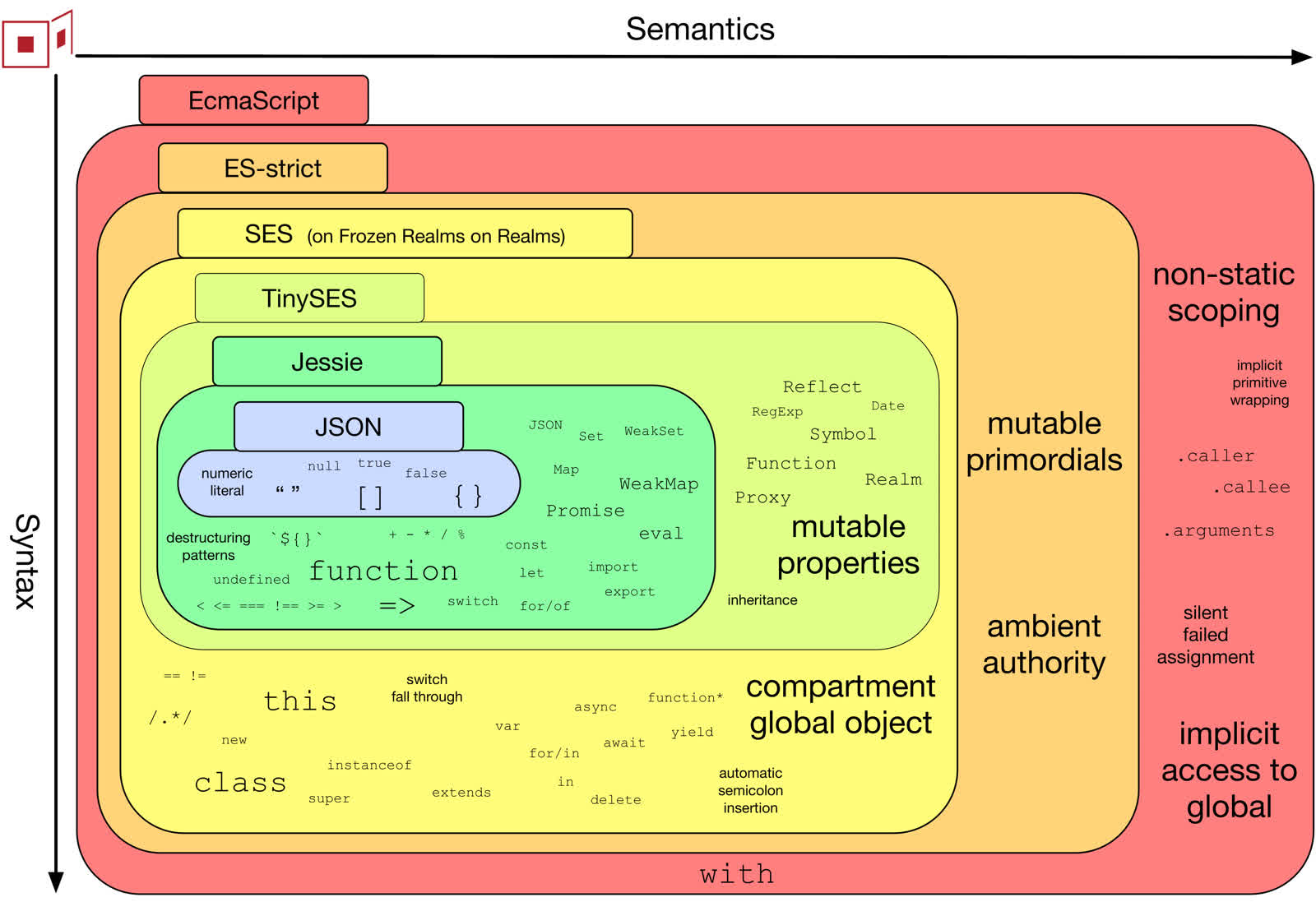
This “math superset of JSON” is almost a universal syntax, common among ALGOL/C-like languages. When an expression is parsed, the abstract syntax tree is essentially a kind of Lisp.
['+', a]; // unary operator `+a`
['+', a, b]; // binary operator `a + b`
['+', a, b, c]; // n-ary operator `a + b + c`
['()', a]; // group operator `(a)`
['()', a, b]; // access operator `a(b)`
[, 'a']; // literal value `'a'`
'a'; // variable (from scope)
null|empty; // placeholder
It may be related to a paper I was reading recently:
Justin is used in a view library called Sprae, where expressions in special HTML attributes are evaluated to achieve dynamic templates using signals for reactivity.
<li :each="item in items" :ref="li">
<input :onfocus..onblur="e => (li.classList.add('editing'), e => li.classList.remove('editing'))"/>
</li>
Reactivity is the way a system reacts to data changes.
Similarly HTMX is a library that provides magic HTML attributes, and has a companion microlanguage called _hyperscript.
htmx gives you access to AJAX, CSS Transitions, WebSockets and Server Sent Events directly in HTML, using attributes, so you can build modern user interfaces with the simplicity and power of hypertext
<div _="on click wait 5s send hello to .target">
<div _="init fetch https://stuff as json then put result into me">Using fetch() API...</div>
They’re all kinda ugly, as syntax and conceptually, but I find it interesting that there are so many variants of this basic idea, attempts at hacking HTML into a dynamic language for describing the user interface. I won’t mention React, Vue, Angular, or Web Components, which all seem like differently misguided approaches to UI as Code.
<div class="p-6 max-w-sm mx-auto bg-white rounded-xl shadow-md flex items-center space-x-4">
<div class="flex-shrink-0">
<div class="text-xl font-medium text-black">ChitChat</div>
<p class="text-gray-500">You have a new message!</p>
<button className="rounded px-2.5 border-solid border-2 border-black bg-blue-500 text-white">
Click me
</button>
</div>
</div>
Pax: User interface language with an integrated vector design tool, built in Rust
This is a unique angle, creating a cross-platform template language designed to integrate with a visual builder. The code side is familiar-looking syntax that provides behavior and styles.
As a contrasting approach to “UI as Code”, there’s “UI as Data”. Part of the difficulty with HTML template languages seems to be that they blur the line between code and data.
If we’re stuck describing user interfaces as some kind of tree-structured data like HTML/JSON/Lisp.. There’s Pug, a Python-like dialect.
ul
each item in ['Apple', 'Banana', 'Orange']
li= item
if isAuthenticated
p Welcome back!
else
p Please log in.
When it’s reduced to the essential building blocks, a UI view template - including web/desktop/mobile applications - has a quality similar to mathematical expressions and operations.
Feels like we’re missing a shared vocabulary to describe the entire space of what user interface is/does/can be, a unified system of design and behavior. There’s also a question of where a hypertext document becomes a web application.
Dhall looks like what I was looking for: a language designed for something less than Turing-complete.
The various examples from the Web world are less obvious to judge for me. They look more like attempts at sandboxing or better DX than at lowering the power of computation. Even a math expression evaluator can be Turing-complete if it includes conditions and recursion.
On the other hand, these examples are clearly in the “UI as code” theme.
Thanks also to @eliot & all - Justin is super-interesting since I’d also noticed this “universal syntax, common among ALGOL/C-like languages” and wondered if it had been delineated by someone.
Going in the other direction I should point to JSON5, JSON6, JSOX etc. since I think the “JSON+X” idiom seems pretty fertile, though noone has quite added just the superset I’d want.
Branching out from SQL there is Datalog, a Turing-incomplete query language which syntactically a subset of Prolog.
Likewise I’m also very appreciative of Dhall, thanks so much for the link.
So I see what I did was the latter, listing specific examples of such DSLs with ad-hoc design, particularly template languages that are used to describe user interfaces. They’re seemingly invented with no unifying or shared pricinples, at least not explicitly or consciously.
But there are some converging concepts, such as one-way data flow, view as function of state, signals to propagate state changes, and often a microlanguage like hyperscript, extended HTML, or JSON+X syntax to provide a limited form of programming.
From Dhall I learned:
Total functional programming is a programming paradigm that restricts the range of programs to those that are provably terminating.
This sounds like a subset of what you wanted, a theory of programming language design with a focus on controlled freedom and power - including the (in)ability of infinite recursion or otherwise iterating forever. So it’s an opt-in capability of a program, which by default is guaranteed to terminate.
It reminds me of a sandboxed environment of a virtual machine, with limited memory, processing (like how many steps of code are executed per second), file system or network access, device I/O.. It’s common for the host to be able to terminate a program at any time, or allow the (non-)termination of a program by maximum number of steps, iteration/recursion.
Interesting that such capabilities can be enforced on the “machine”-level (the host environment running the program); by the language runtime; or on the level of language design by making certain operations or computation (im)possible.
What if I think from the opposite side: a programming language that can do nothing, with no freedom or power. I mean, that’s where it would start by default. For example, microlanguages like..
null that does nothing given any code
echo that simply outputs the given code
math that evaluates a mathematical expression
eval that evaluates a C-like common syntax: JSON primitives, arithmetic operations, variables, conditions, loops, functions..
Somewhere between echo and math would be data formats like json and yaml. There’s a Linux command expr, which evaluates an expression of some kind of DSL (Bash?). Oh and regular expressions is a small language with limited capability, for commands like grep, that can only do pattern matching (sometimes infinitely)..
So a language can act like a filter in a pipeline, transforming input to output, sometimes allowed to interact and have effects on the external environment.
TopoLang is an experimental programming “language” based on topological pattern matching in images. In the example below there is a single rule, the left side is repeatedly matched and replaced by the right side.
I love this kind of unconventional computing that challenges what a language can be, and what computation means.
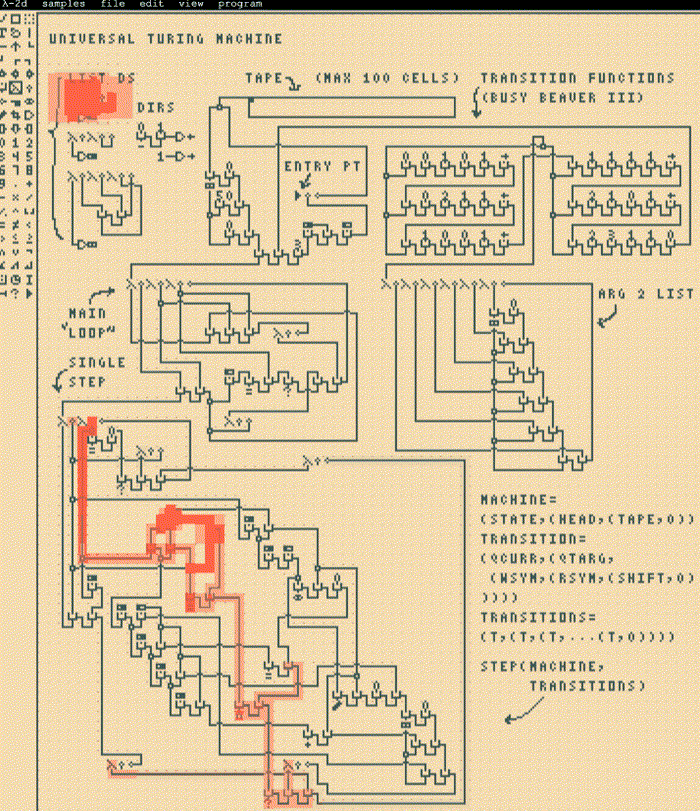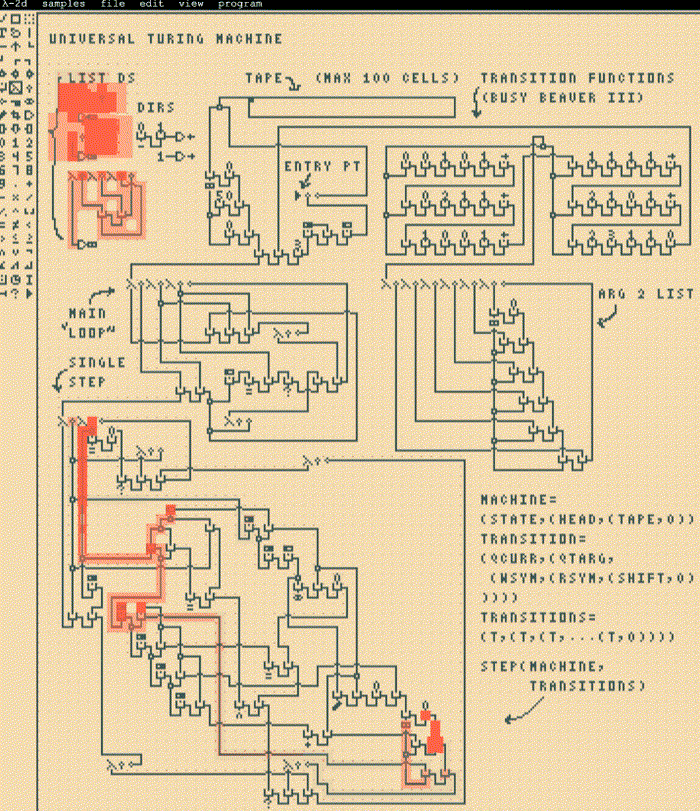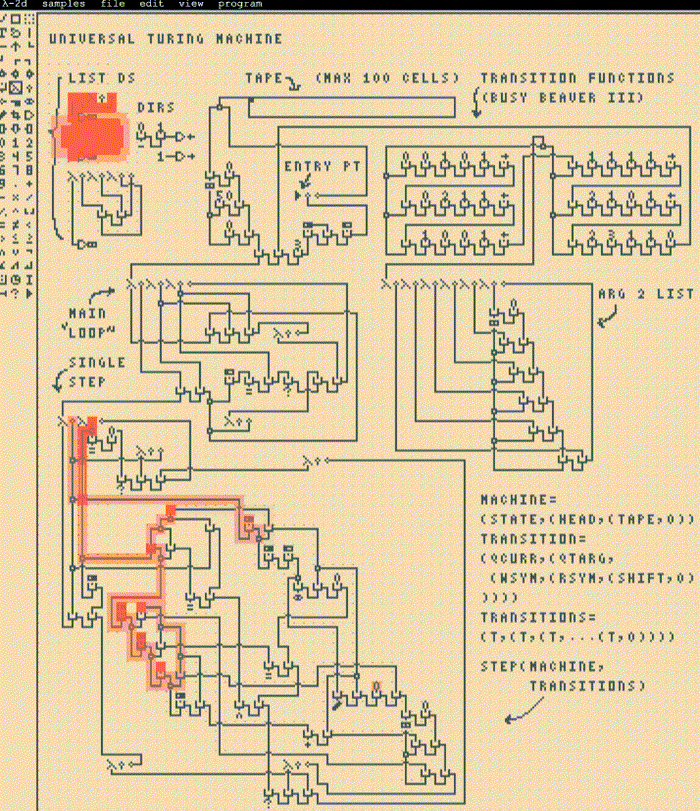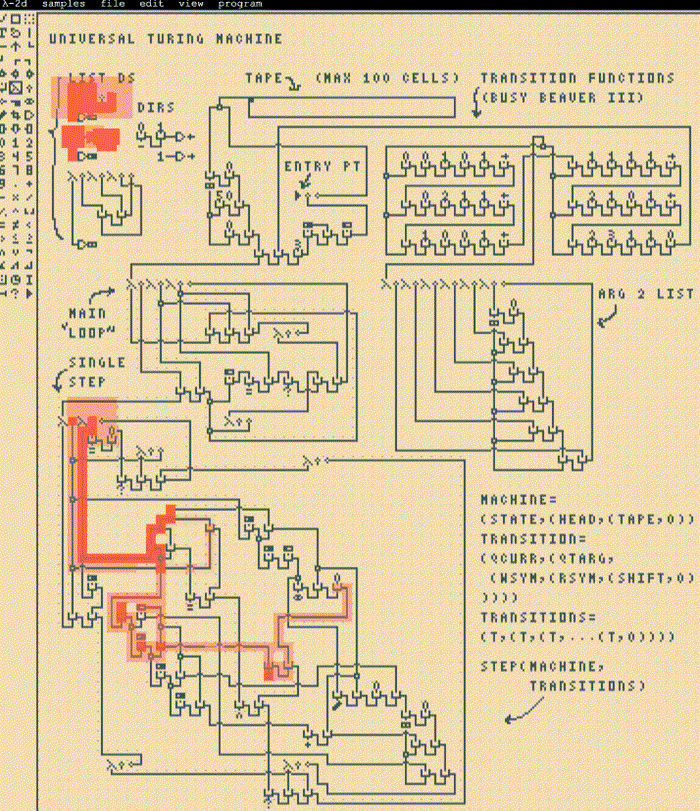
In computability theory, a system of data-manipulation rules (such as a model of computation, a computer’s instruction set, a programming language, or a cellular automaton) is said to be Turing-complete or computationally universal if it can be used to simulate any Turing machine. This means that the system is able to recognize or decode other data-manipulation rule sets. Turing completeness is used as a way to express the power of such a data-manipulation rule set.
To show that something is Turing-complete, it is enough to demonstrate that it can be used to simulate some Turing-complete system. ..If the limitation of finite memory is ignored, most programming languages are otherwise Turing-complete.
A system of data-manipulation rules. That describes a computer, a language, a program, and cellular automata - they all perform computation by applying rules. Some rulesets are universal/complete, others are less so or not at all, by design or as an emergent property.
Fascinating how the “ultimate power” of being Turing complete and computationally universal is the ability to fully simulate a computer or another Turing-complete machine. That’s the other end of the spectrum, a programming language that can do everything.
How does that relate to UI as Code? Apparently the user interface is a kind of computer with inputs and outputs; and the language used to build that machine has more or less power and capability, between data (static) and code (dynamic).
I read somewhere that the UI can be considered as another kind of API (application programming interface), with a set of available actions and data from the user as input, and the UI responds with state changes, possibly making available more actions.
An interface definition language (IDL) is a generic term for a language that lets a program or object written in one language communicate with another program written in an unknown language. IDLs are usually used to describe data types and interfaces in a language-independent way.
IDLs are commonly used in remote procedure call software. In these cases the machines at either end of the link may be using different operating systems and computer languages. IDLs offer a bridge between the two different systems.
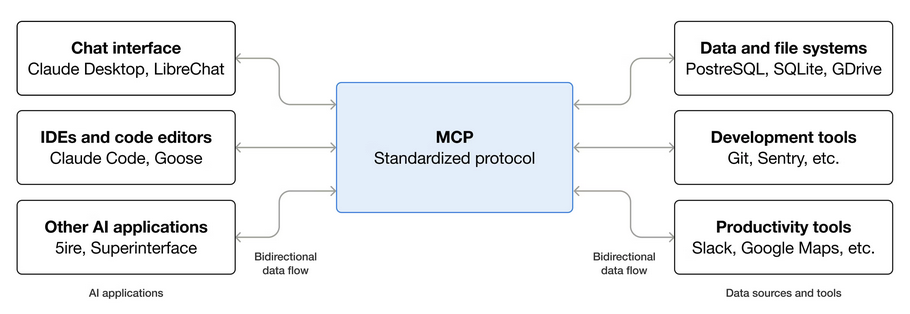
The Model Context Protocol (MCP) is an open-source framework to standardize the way artificial intelligence (AI) systems like large language models (LLMs) integrate and share data with external tools, systems, and data sources. MCP provides a universal interface for reading files, executing functions, and handling contextual prompts.
So an API can be considered a kind of “language” with a set of available verbs and nouns. They’re almost never supposed to be Turing complete, instead providing little to no capability by default and only through authentication a user gains permission. Even then, there is no “complete freedom” and power over the resources, which are guarded beyond the hard separation between client and server.
JsonLogic is a data format for expressing and evaluating logic rules, implemented in various languages (JavaScript, PHP, Python, Ruby, Go, Java, .NET, C++).
Build complex rules, serialize them as JSON, share them between front-end and back-end.
JsonLogic isn’t a full programming language. It’s a small, safe way to delegate one decision. You could store a rule in a database to decide later. You could send that rule from back-end to front-end so the decision is made immediately from user input. Because the rule is data, you can even build it dynamically from user actions or GUI input.
JsonLogic has no setters, no loops, no functions or gotos. One rule leads to one decision, with no side effects and deterministic computation time.
It has a small set of data types, logical and numeric operations, as a limited language that always evaluates to true or false.
BlooP (Bounded loop) is a simple programming language designed by Douglas Hofstadter to illustrate a point in his book Gödel, Escher, Bach.
It is a Turing-incomplete language whose main control flow structure is a bounded loop (i.e. recursion is not permitted). All programs in the language must terminate, and this language can only express primitive recursive functions.
Common Expression Language (CEL) is a non-Turing complete language designed for simplicity, speed, safety, and portability. It implements common semantics for expression evaluation, enabling different applications to more easily interoperate.
CEL is designed to be embedded in an application, with application-specific extensions, and is ideal for extending declarative configurations that your applications might already use. Suitable for things like list filters for API calls, validation constraints on protocol buffers, and authorization rules for API requests.
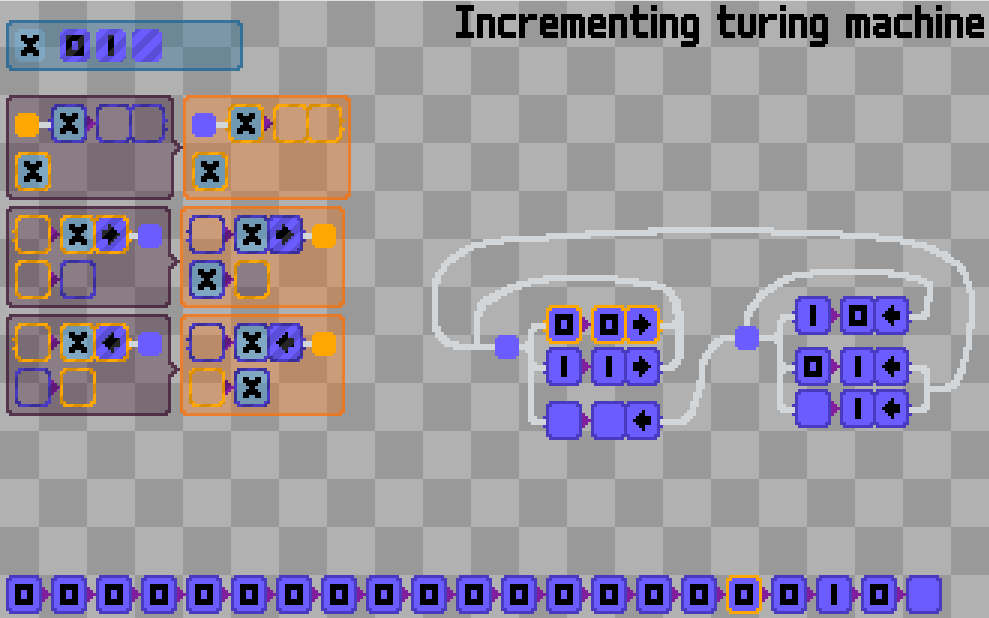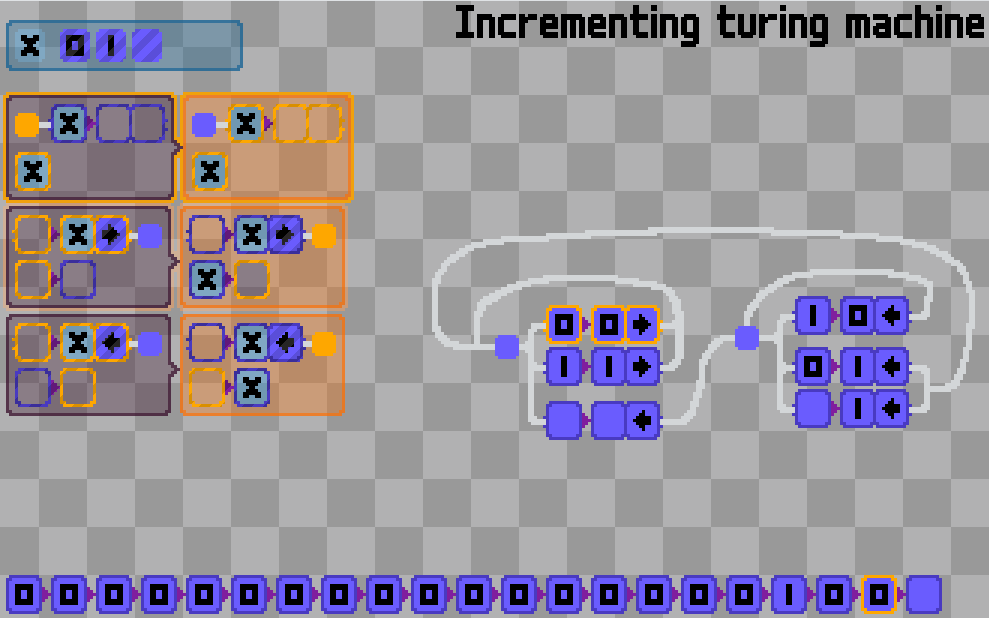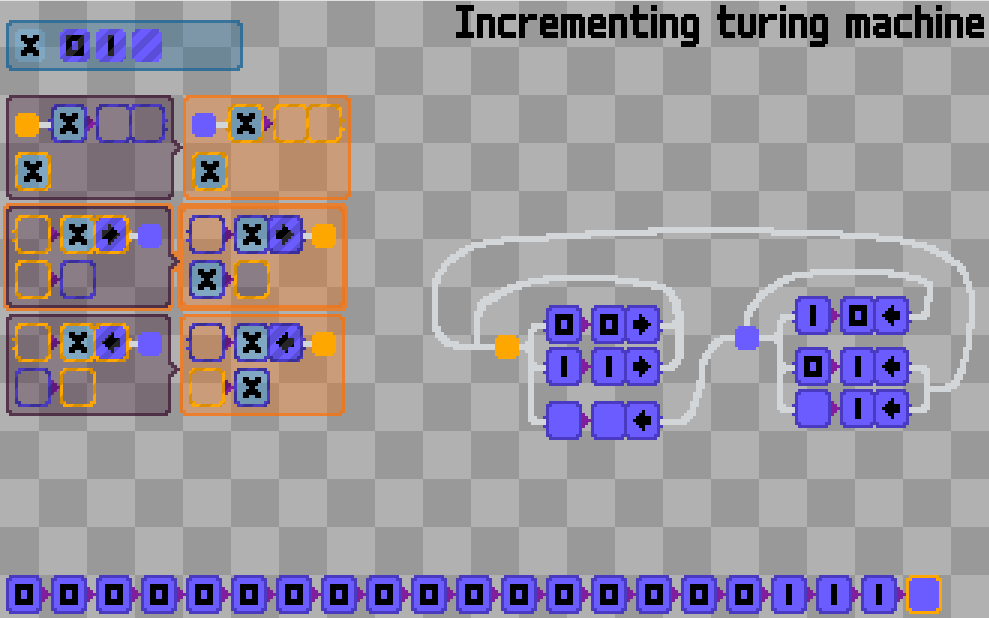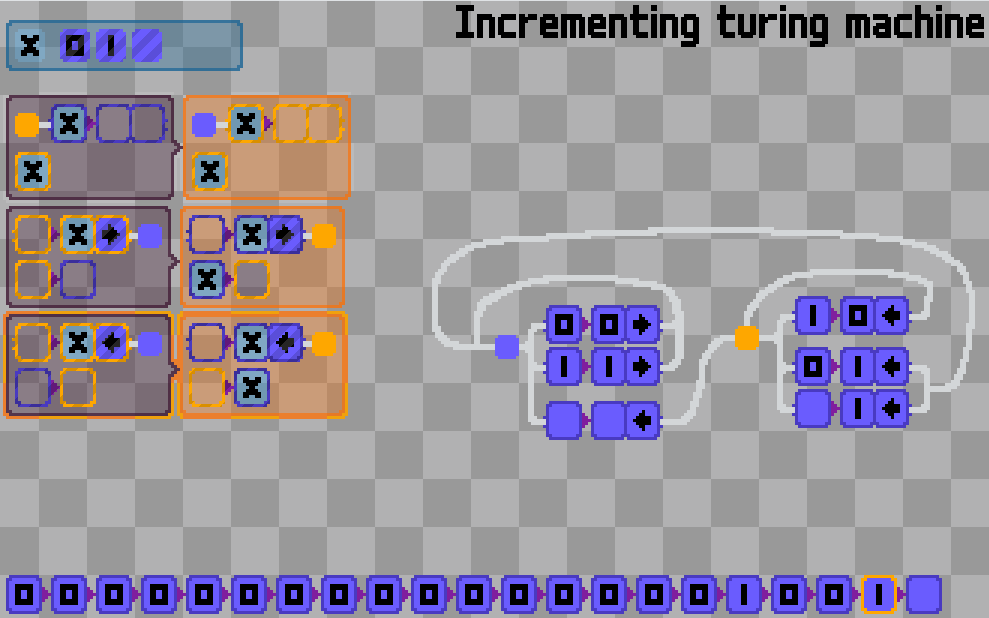
Is there a “smallest possible” programming language? A minimal set of rules that is still able to “compute”.. I guess something like lambda calculus.
In algorithmic information theory (a subfield of computer science and mathematics), the Kolmogorov complexity of an object, such as a piece of text, is the length of a shortest computer program that produces the object as output.
It is a measure of the computational resources needed to specify the object, and is also known as algorithmic complexity, program-size complexity, descriptive complexity, or algorithmic entropy.
Ah, so this is about smallest program, not smallest language.
Time-bounded Kolmogorov complexity is a modified version of Kolmogorov complexity where the space of programs to be searched for a solution is confined to only programs that can run within some pre-defined number of steps.
Kolmogorov complexity has been used in the context of biology to argue that the symmetries and modular arrangements observed in multiple species emerge from the tendency of evolution to prefer minimal Kolmogorov complexity.
..Considering the genome as a program that must solve a task or implement a series of functions, shorter programs would be preferred on the basis that they are easier to find by the mechanisms of evolution.
An example of this approach is the eight-fold symmetry of the compass circuit that is found across insect species, which correspond to the circuit that is both functional and requires the minimum Kolmogorov complexity to be generated from self-replicating units.
OK, so we’ve arrived at “User as Code”.
From the perspective of a programming language (or user interface) the user is code. The user’s intentions can only be expressed through the words provided by the language or interface.
With each word the user gains some (possibly quantifiable) degree of freedom and power. With enough words, the user reaches Turing completeness and computational universality where anything is possible within that given realm.
Later I was talking with a friend about the deliberate restriction of technology: the Amish with no cars, television, computers, or phones; how in Islam the visual representation of living beings - making of images - is prohibited (aniconism), leading to elaborate use of geometry in architecture and decoration; and a branch of orthodox Judaism where on certain days it is forbidden to use electricity, smart phones (but classic voice phones and text messages are allowed); or even to press a button. Apparently pressing a button is considered “work”, as one of the Rabbinically prohibited activities of Shabbat.
To press a button is so symbolic of technology and programming. It’s about the convenience of automation and machines, it’s the unnatural/ungodly power of human intelligence and creativity to make things happen. It’s Daedalus and his son Icarus with artificial wings. It’s Prometheus stealing fire from the gods, worthy of punishment. To press the button is to eat the forbidden fruit, the sin of knowledge. The big red button detonates the secret power of atoms.
There’s a genre called one-button games, surprisingly rich with varieties of expression.
A button is a primitive form of user interface with two states: up and down. So I imagine a microlanguage called uno with only a single instruction; and dos with two instructions.
What kind of computation can one achieve with a single word? The game depends on the context and what the button does. With two words already I smell a Turing-complete user interface.
Lambda calculus is such a concise language that it only has two instructions: that of function application and that of function definition.
I quickly came up with working symbols for each: a “cup” shape for the former (for the silly intuition that applying the function is like putting the argument into the “cup”), and the eponymous greek letter for the latter.
Then came the wires to connect the symbols and through which data can flow. Technically the language is Turing complete at this point, but will be excruciatingly laborious to use.
Therefore, I added a lot more other symbols you would expect from your favorite programming languages, things like numbers and math operators. Consider them mere syntactic sugars: you can still stick to Church numerals and other “pure” lambda calculus constructs if you’d like.
Thanks for another one of your great overviews on a topic!
Total functional programming as in Dhall (or BlooP) is indeed the kind of principle I was looking for. But in retrospect, all the ad-hoc languages, e.g. built on top of JSON, are interesting as well because they illustrate what people care about in this field. I hadn’t suspected that there are so many of them!
My own interest in this are is not so much “UI as code” but “Code as UI”. In a malleable system for end-user programming, based on code, the languages of the code are a core aspect of the system’s user interface. My question then is: which useful guarantees can be baked into such a language to reduce the cognitive load for its users? Termination is clearly one of them.
If you start from the other end, i.e. a data language with no computation, and then add computational features, you will probably end up with something highly specific for some use cases. Which can be a good approach as well, of course.
Some of these “code as UI” features are about language design, and others are enabled by the software ecosystem around the language, like the editor and dev/build tools. But I suppose the ecosystem and community are as important to the user of a language as its grammar and syntax.
Code editors have features specifically designed to simplify and speed up typing of source code, such as syntax highlighting, indentation, autocomplete and brace matching functionality. These editors may also provide a convenient way to run a compiler, interpreter, debugger, or other program relevant for the software-development process.
Structure editors can be used to edit hierarchical or marked up text, computer programs, diagrams, chemical formulas, and any other type of content with clear and well-defined structure
Already in '86 he was thinking of “adaptable, flexible, extendable, and customizable systems”. The Gandalf project was about generating “families of software development environments semiautomatically”.
An apparently well-known structure editor is:
JetBrains MPS (Meta Programming System) is a language workbench developed by JetBrains. MPS is a tool to design domain-specific languages (DSL). It uses projectional editing which allows users to overcome the limits of language parsers, and build DSL editors, such as ones with tables and diagrams. It supports language-oriented programming.
A projectional editor allows the user to edit the Abstract syntax tree (AST) representation of code in an efficient way. It can mimic the behavior of a textual editor for textual notations, a diagram editor for graphical languages, a tabular editor for editing tables and so on. The user interacts with the code through intuitive on screen visuals which they can even switch between for multiple displays of the same code.
That makes sense, like different views into the same data structure.
Xtext is an open-source software framework for developing programming languages and domain-specific languages (DSLs). Unlike standard parser generators, Xtext generates not only a parser, but also a class model for the abstract syntax tree, as well as providing a fully featured, customizable Eclipse-based IDE.
So these are “language design environments” to define a grammar and generate parsers, code, and even DSL editors.
To specify a language, the developer has to write a grammar in Xtext’s grammar language.. From that definition, a code generator derives an ANTLR parser and the classes for the object model. Xtext includes features which integrate well with the Eclipse-based IDE:
Some of the examples I found above are more about reducing the cognitive load of language designers. Which, I suppose in turn helps with developing or generating useful language features for users.
As a field of research, human–computer interaction is situated at the intersection of computer science, behavioral sciences, design, media studies, and several other fields. The term is intended to convey that, unlike other tools with specific and limited uses, computers have many uses which often involve an open-ended dialogue between the user and the computer.
Recently I was thinking how communication and computation are related - and might even be the same thing essentially. And coincidentally, after I wrote about a button being a primitive user interface, I learned there’s a book called The Switch, based on a series of articles about the digital switch and the early history of computers, an “expeditious method of conveying intelligence”.
A button or switch adds to a system a degree of malleability (one malley) with a signal of 0 or 1, the basic unit of interface and input/output, through which a user can express their intention or decision. Or even a message like with Morse code.
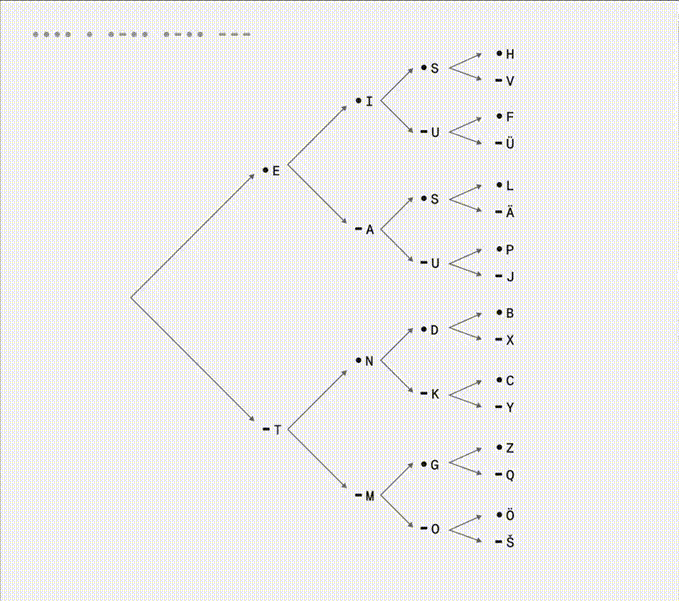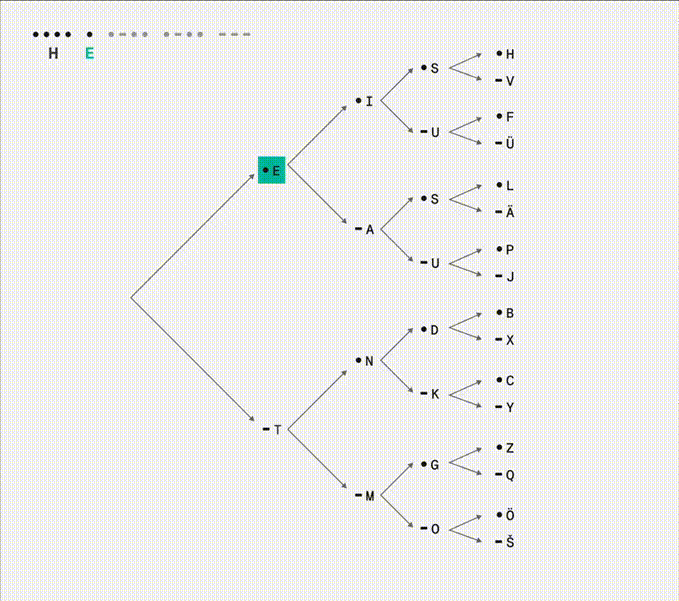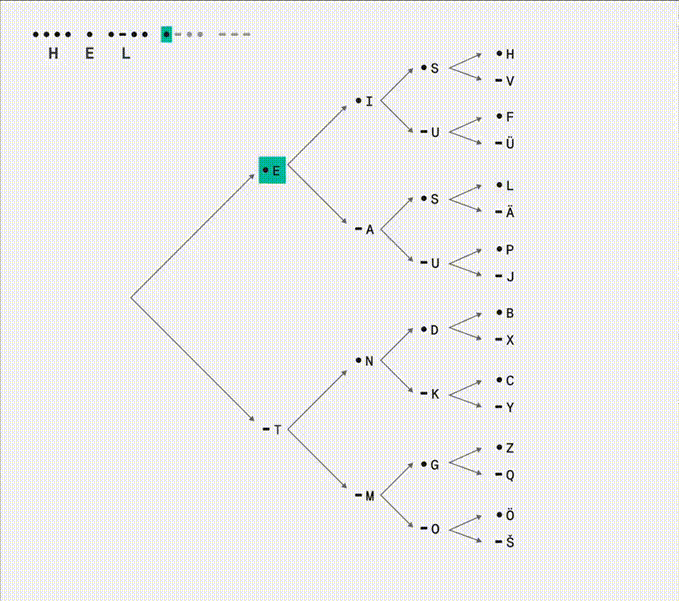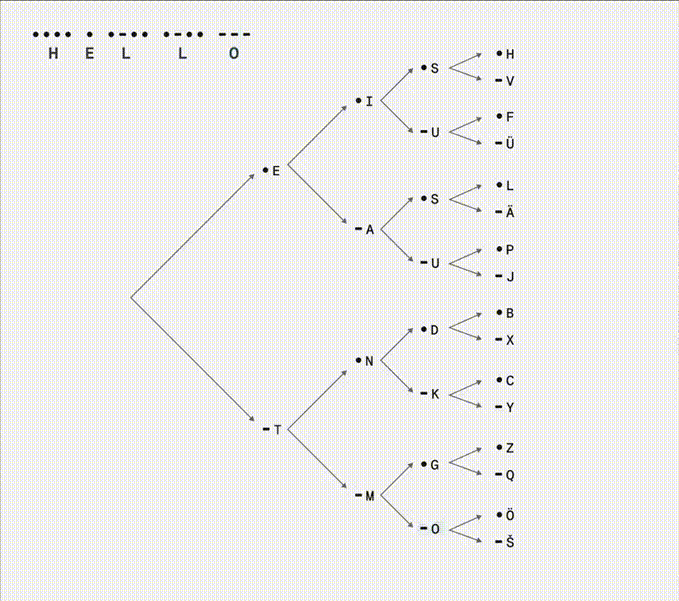
I see now Morse code is made of not two but three instructions: dit •, dah -, and a space of silence between letters. A clever way of using a single button and the time axis to express the entire alphabet. I like that the more frequently used letters are shorter and closer to the root.
Above binary tree animation from a tweet. There’s a mistake in branch E-A, the S and U should be R •-• and W •--. In a reply someone called this tree a state machine, something I’ve been thinking about since seeing an interactive example recently:
That’s a user interface alright.. I thought if I break down the problem to its primitives I would understand it better, but I’m impressed by how much complexity a simple interface can embody. So I see that an interface is a layer of abstraction to hide the machinery inside and expose a limited set of controls, to reduce the cognitive load on the user.
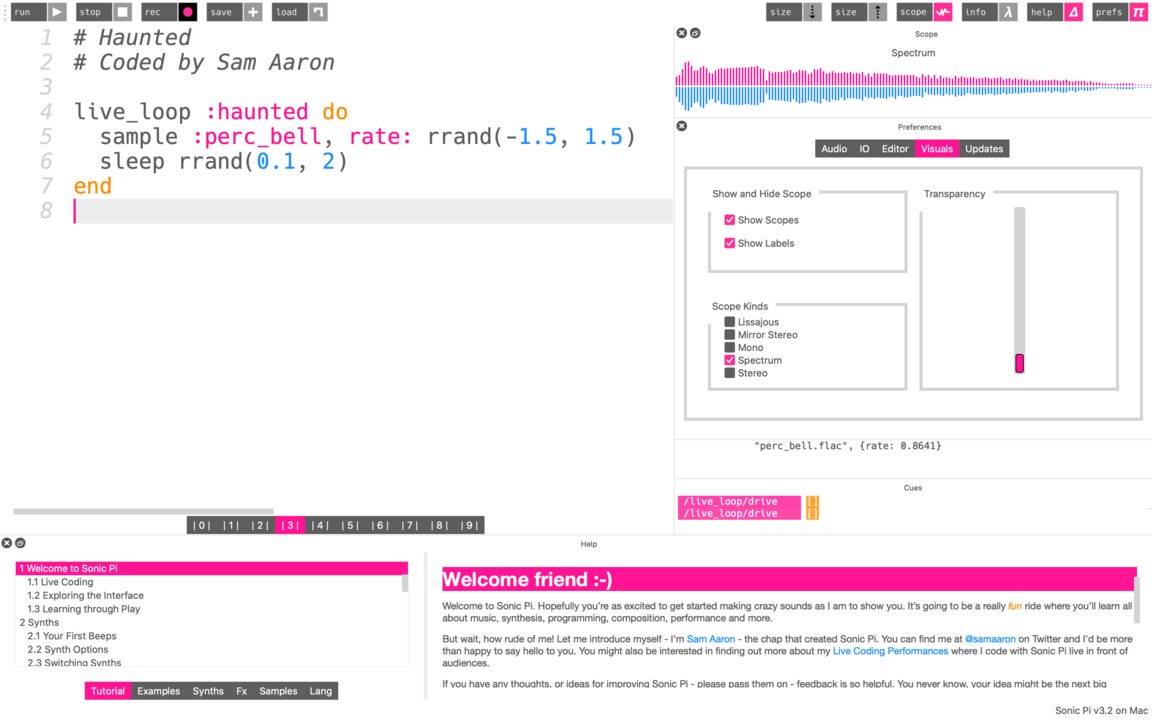
Live coding environments, particularly with generative music and visuals, is using code as an interface to a living system.
Live coding, sometimes referred to as conversational programming, makes programming an integral part of the running program. It is most prominent as a performing arts form and a creativity technique centred upon the writing of source code and the use of interactive programming in an improvised way.
Live coding is often used to create sound and image based digital media, as well as light systems, improvised dance and poetry, though is particularly prevalent in computer music usually as improvisation, although it could be combined with algorithmic composition.
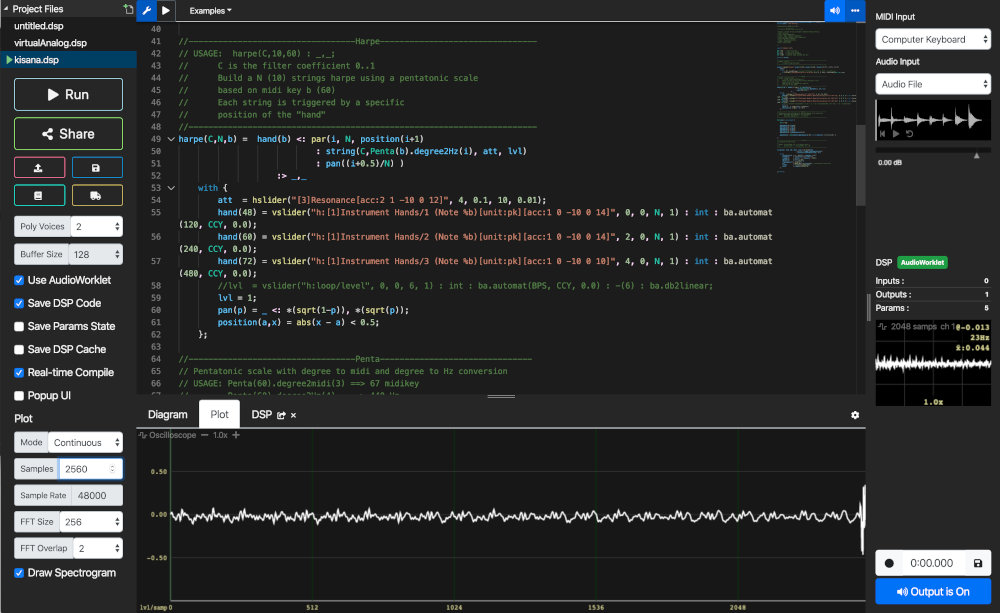
DawDreamer can create directed acyclic graphs of audio processors such as VSTs which generate or manipulate audio streams. It can also dynamically compile and execute code from Faust, a powerful signal processing language which can be deployed to many platforms and microcontrollers.
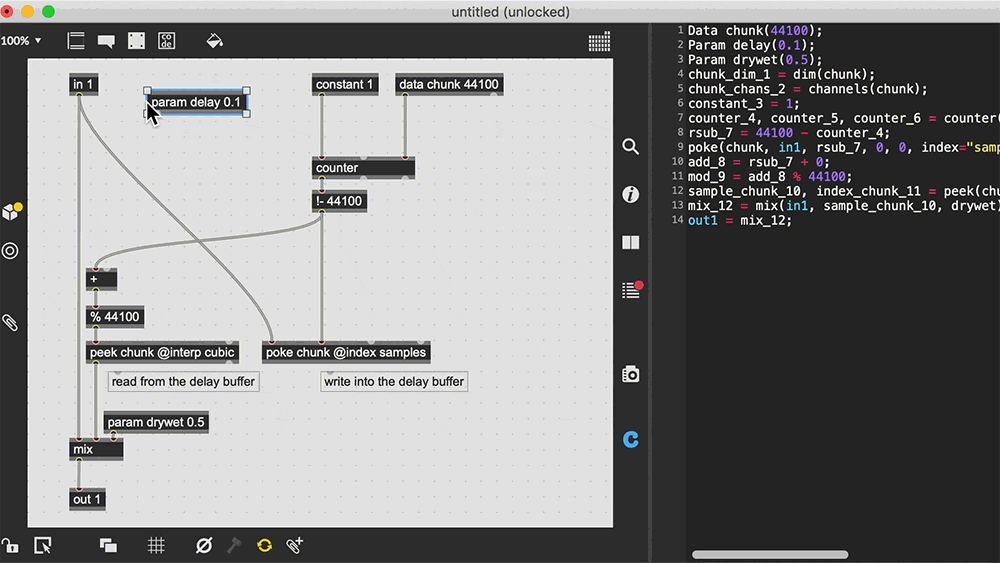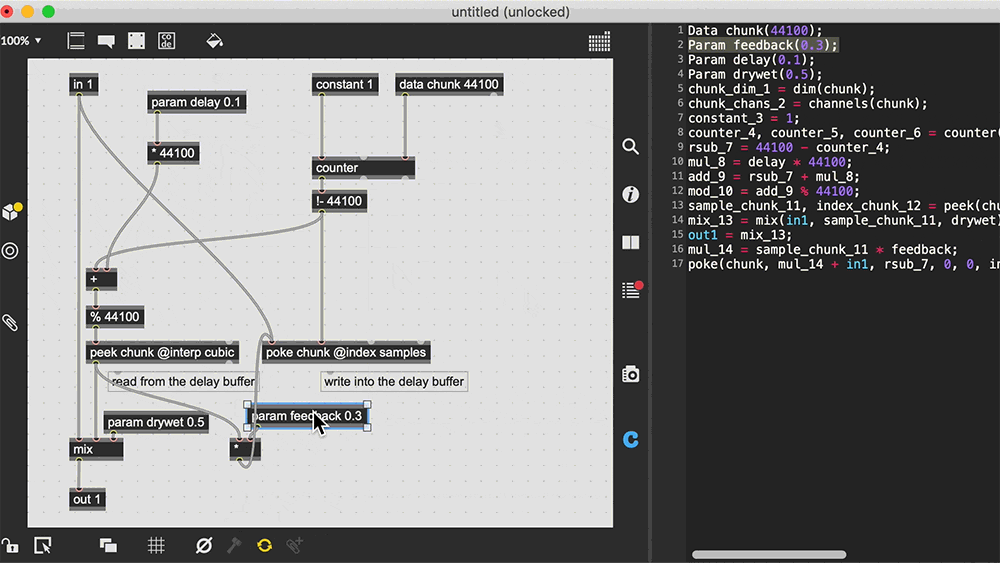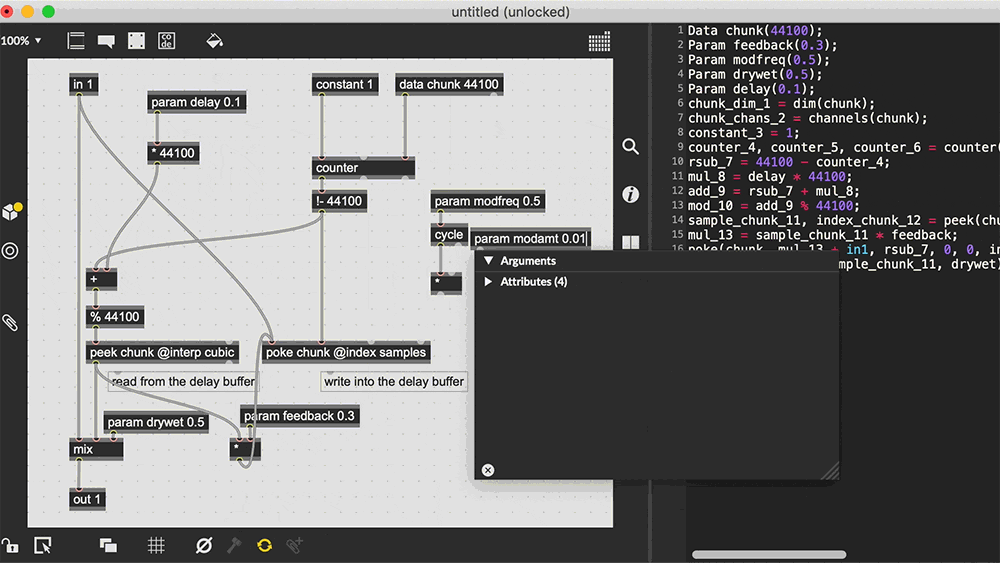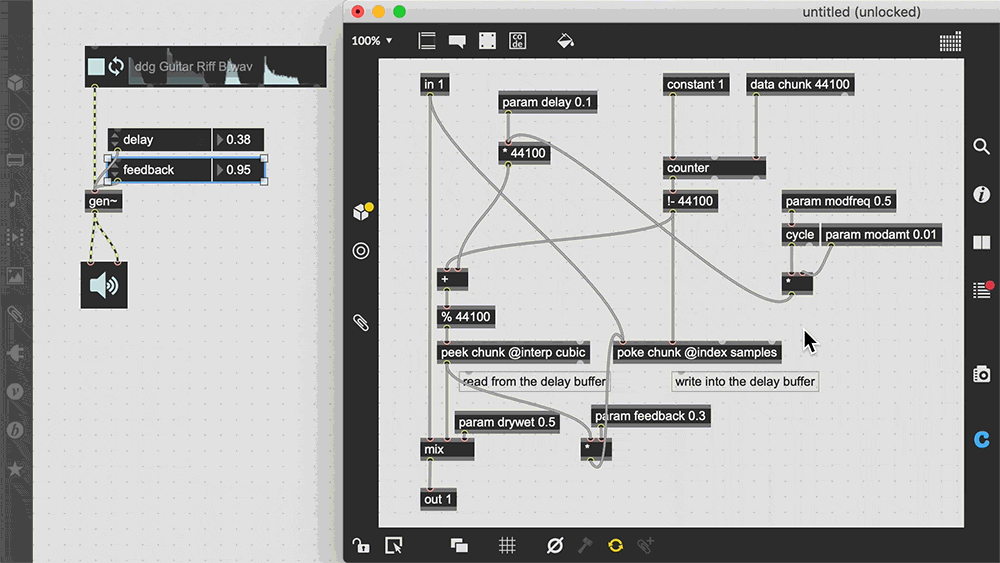
Max, also known as Max/MSP/Jitter, is a visual programming language for music and multimedia.. Over its more than thirty-year history, it has been used by composers, performers, software designers, researchers, and artists to create recordings, performances, and installations.
Pd enables musicians, visual artists, performers, researchers, and developers to create software graphically without writing lines of code. Pd can be used to process and generate sound, video, 2D/3D graphics, and interface sensors, input devices, and MIDI.
Pd can easily work over local and remote networks to integrate wearable technology, motor systems, lighting rigs, and other equipment. It is suitable for learning basic multimedia processing and visual programming methods as well as for realizing complex systems for large-scale projects.
Well, Max and PureData may be too far of a tangent, a node/graph editor for underlying code and data.
There’s something intriguing about different ways to visualize programs and computation, views and interfaces to create and interact with the running code.
A hardware description language enables a precise, formal description of an electronic circuit that allows for the automated analysis and simulation of the circuit.
A hardware description language looks much like a programming language such as C or ALGOL; it is a textual description consisting of expressions, statements and control structures. One important difference is that it explicitly includes the notion of time.
Related: dataflow programming, UML, swim lane diagrams, flow charts.. And I suppose services like Zapier and IFTTT (If This Then That) with user-built automation workflows.
A program as a directed graph of data flowing between operations. Data streams and the propagation of change. Reactive programming like Excel spreadsheets and Observable notebooks.
Surveying historical and modern implementations of code/language as interface and interface as code/data, I guess it’s my way of trying to learn and understand the concepts and principles involved. I’m starting to see some common threads that run through these various concrete examples.
Ideally this food for thought will nourish my own experiments and projects. I like the idea of a live programming system with integrated code editor and visual builder like graphs and tree-structure view, as different modes to interact with the same underlying code as data. Editing the tree will update the code, and vice versa. That MPS Projectional Editor video above, as commercial and proprietary as it is, I had some aha moments about how a rich editor environment can support the design and coding of user interfaces and languages.
Static code analysis is a double-edged sword. It provides guarantees, but at the price of increased cognitive load, as you have to learn the analyzer’s rules and deal with its error messages. That’s often a good trade-off when building large systems, but not for explorative work, which is what I care more about.
Tooling can be a huge help, as I learned from my Smalltalk experience. Tools in an IDE are very similar to DSLs in terms of affordances. But I am not aware of any principles approach to tool-based guarantees. It all seems ad-hoc, like most DSLs.
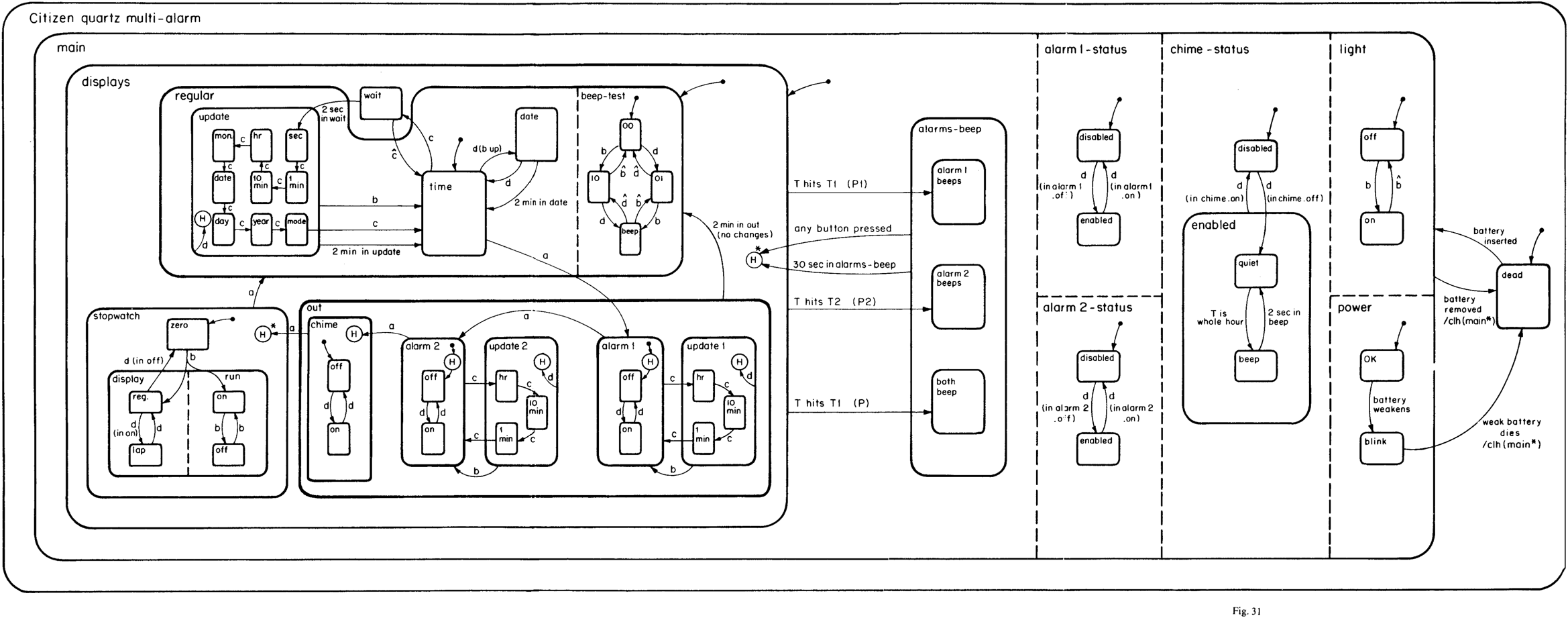
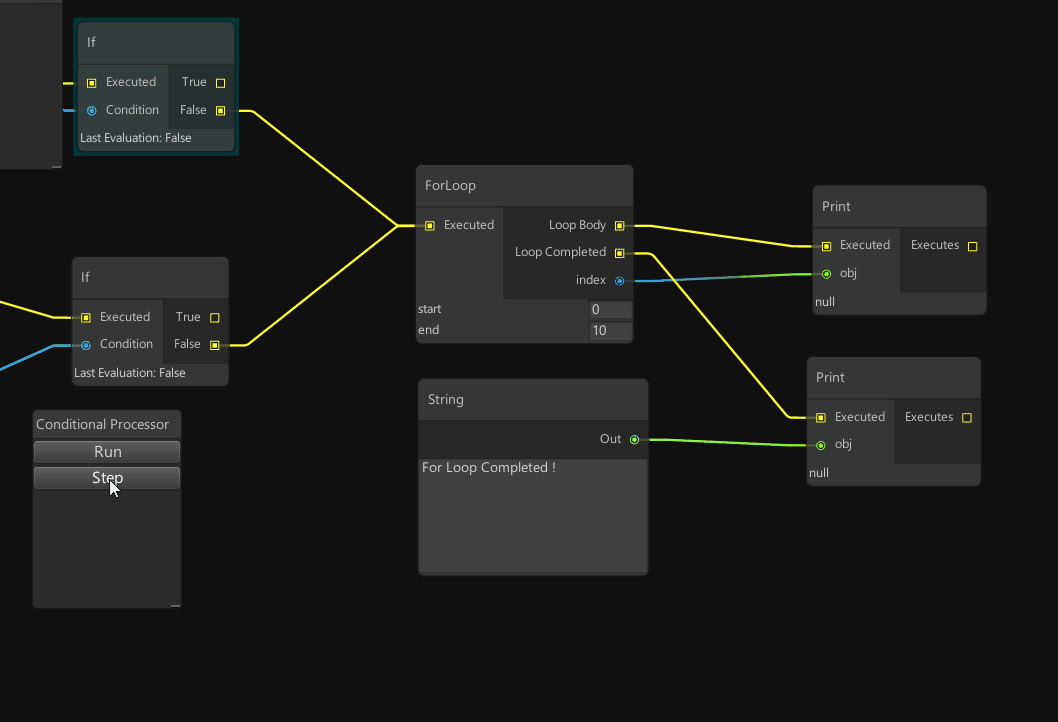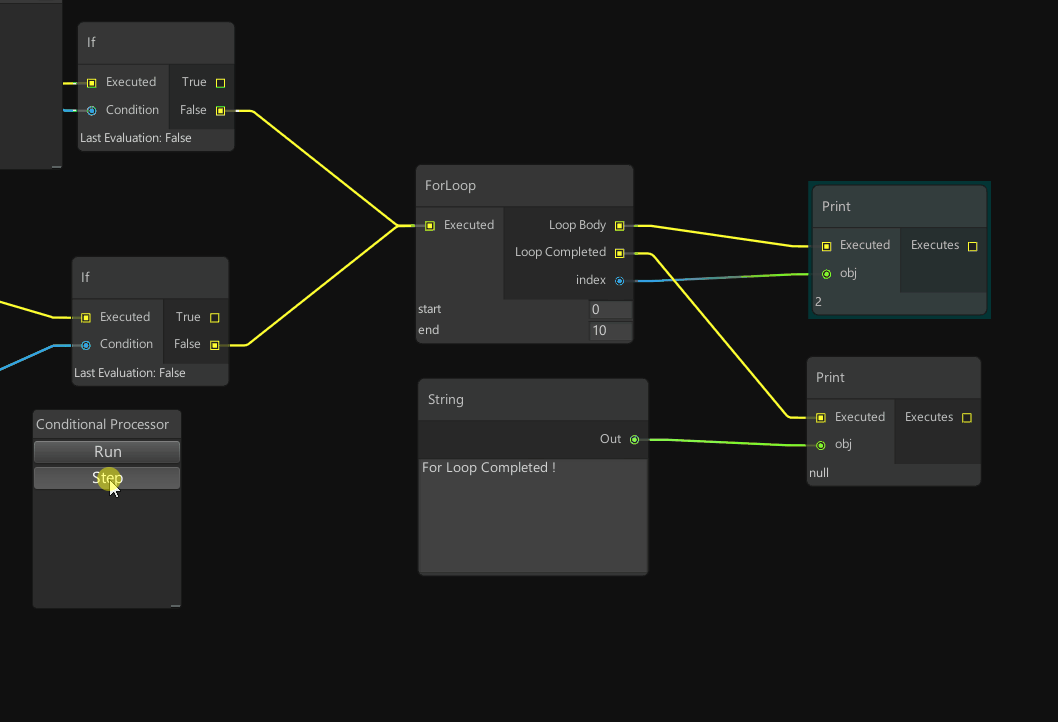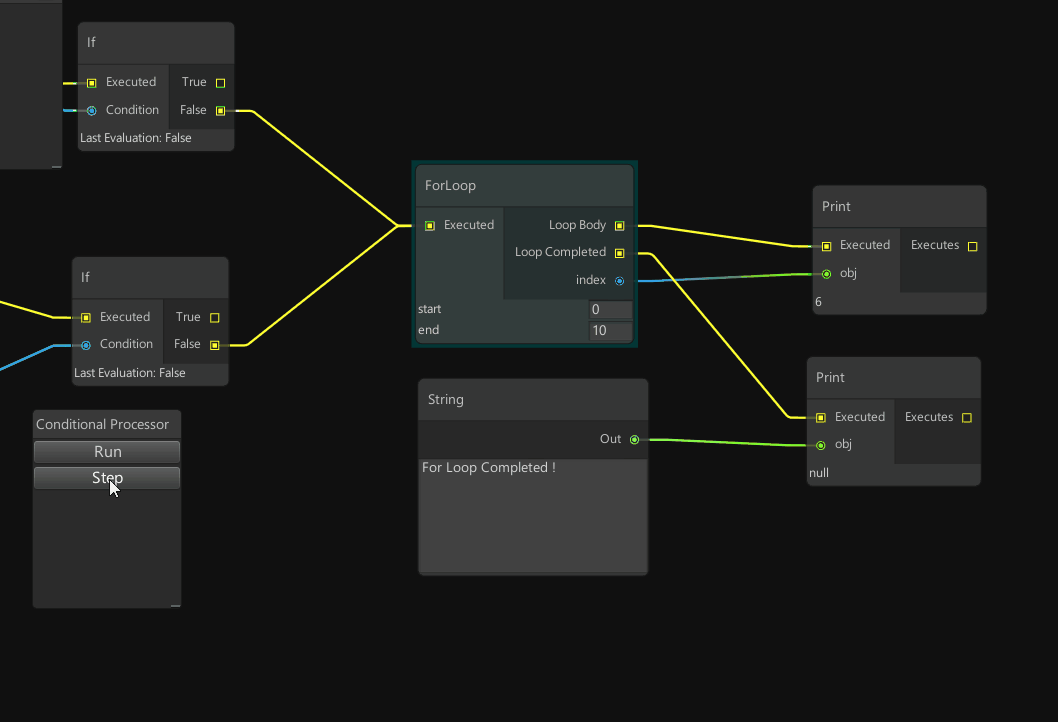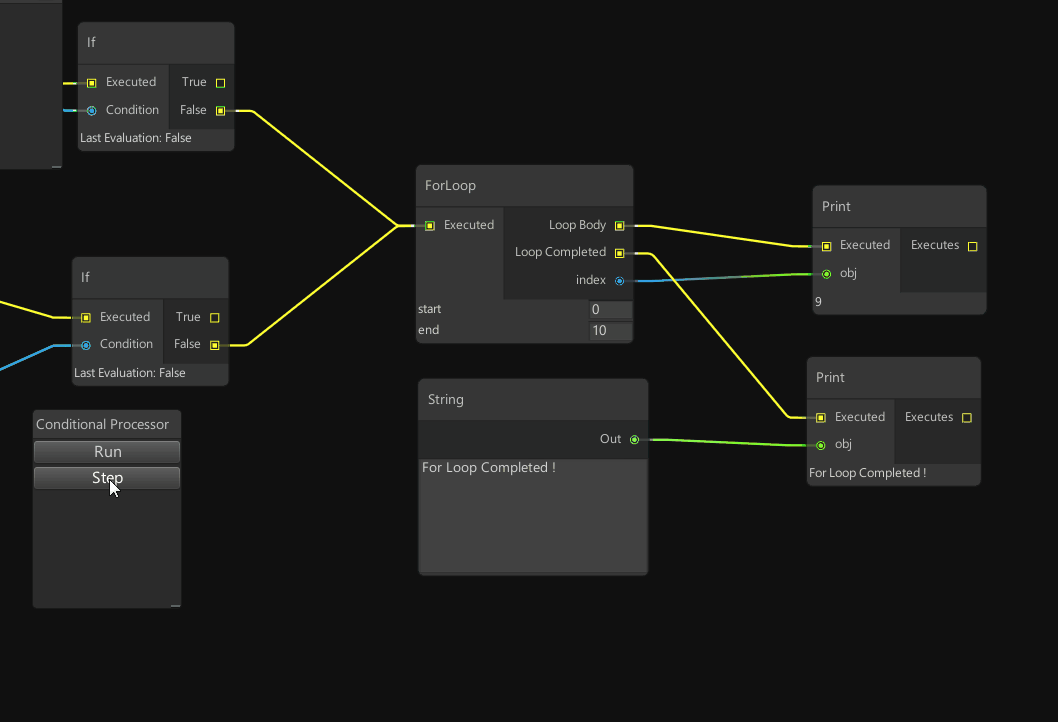
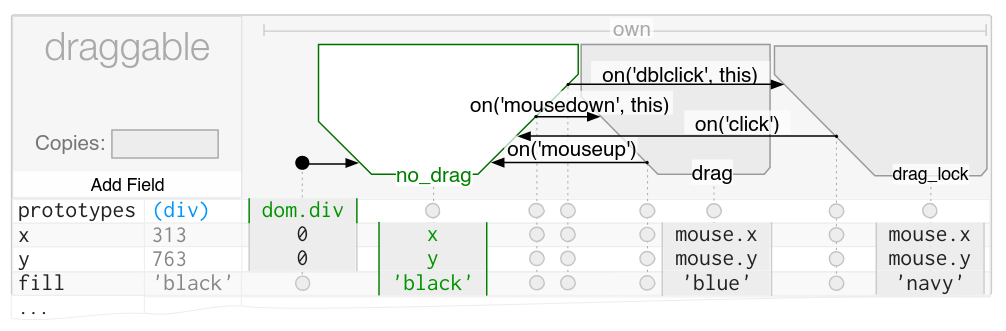
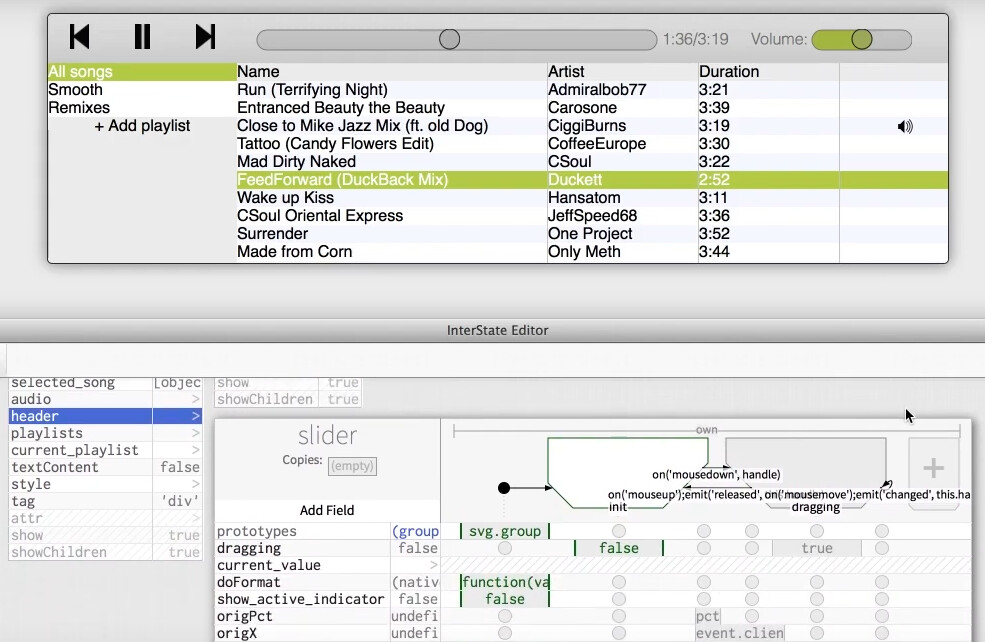
Thank you for this write-up! Your section on state machines reminded me of the wonderful programming language + editor project InterState. It’s a really interesting, and seldomly discussed, implementation of a programming environment developed specifically for “front end” development.
InterState is a thought-provoking experiment, I watched the short demo several times and feel like there’s some insight I want to extract and absorb.
Found its source code at GitHub soney/interstate, archived now. Its website has a link to a paper and a home page but others pages are blank (looks like broken link to jQuery library on a CDN). I’m curious to get them working, maybe as a weekend exercise one day.
InterState: A Language and Environment for Expressing Interface Behavior (PDF)
InterState is a new programming language and environment that addresses the challenges of writing and reusing user interface code. InterState represents interactive behaviors clearly and concisely using a combination of novel forms of state machines and constraints. It also introduces new language features that allow programmers to easily modularize and reuse behaviors.
InterState uses a new visual notation that allows programmers to better understand and navigate their code. It also includes a live editor that immediately updates the running application in response to changes in the editor and vice versa to help programmers understand the state of their program.
To achieve a tabular layout with every state and transition represented in a column, InterState’s visual notation “flattens” its state machines to allocate horizontal space for all local and inherited states. The trapezoidal shape of states is designed to allocate a column for every transition, horizontally centered where the transition’s arrow begins.
Here a music player application is developed by “live coding” in the editor, except there’s no code, it’s more like navigating an interactive table of state machines - objects, their possible states, and events to transition between states.
We evaluated the understandability of InterState’s programming primitives in a comparative laboratory study..with 20 experienced programmers (ages 19-41). We found that participants were twice as fast at understanding and modifying GUI components when they were implemented with InterState than when they were implemented in a conventional textual event-callback style.
We evaluated InterState’s scalability with a series of benchmarks and example applications and found that it can scale to implement complex behaviors involving thousands of objects and constraints.
Some other points stood out in the paper. The language and editor are decoupled from the view renderer, like a virtual DOM.
Manipulating Visual Objects - InterState is output-agnostic and can be made to work with any output supporting a structured graphics model (sometimes called a “retained object model”). We have fully implemented output mechanisms for HTML DOM objects and Scalable Vector Graphics (SVG) objects. We have also created a prototype to confirm the feasibility of using WebGL as an output mechanism for creating 3D interfaces.
And errors in the program are not show-stopping.
InterState’s runtime was designed to enable programmers to always have a running application, like in spreadsheet programming, where constraint errors do not halt updates of other constraints. InterState achieves this by “localizing” errors: constraints with errors only prevent the parts of the program from running that depend on those constraints. In the editor, errors are displayed next to the problematic expression.
The project was partly funded by Adobe. In the conclusion it’s suggested that the “look” of an application can be designed by tools like Photoshop or Illustrator; and the “feel”, the specification of GUI behaviors designed in InterState.
InterState shows how innovations in the execution model, combined with a visual notation and live editor, can work together to enable programmers to express interactive behaviors concisely and naturally.
It’s a unique synthesis of spreadsheet-like visual programming system and state machines.
The main author of InterState runs an academic research group called SPOT with further explorations and publications, focused on “understanding the factors that make programming tools usable and designing & building new tools for programmers.”
Programming offers new opportunities for visual art creation, but understanding and manipulating the abstract representations that make programming powerful can pose challenges for artists who are accustomed to manual tools and concrete visual interaction.
We hypothesize that we can reduce these barriers through programming environments that link state to visual artwork output. We created Demystified Dynamic Brushes (DDB), a tool that bidirectionally links code, numerical data, and artwork across the programming interface and the execution environment — i.e., the artist’s in-progress artwork.
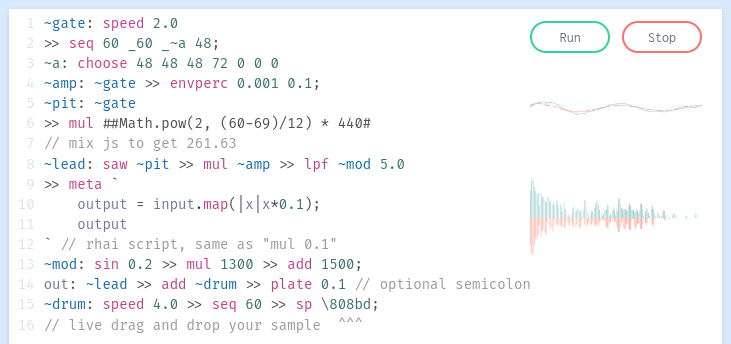
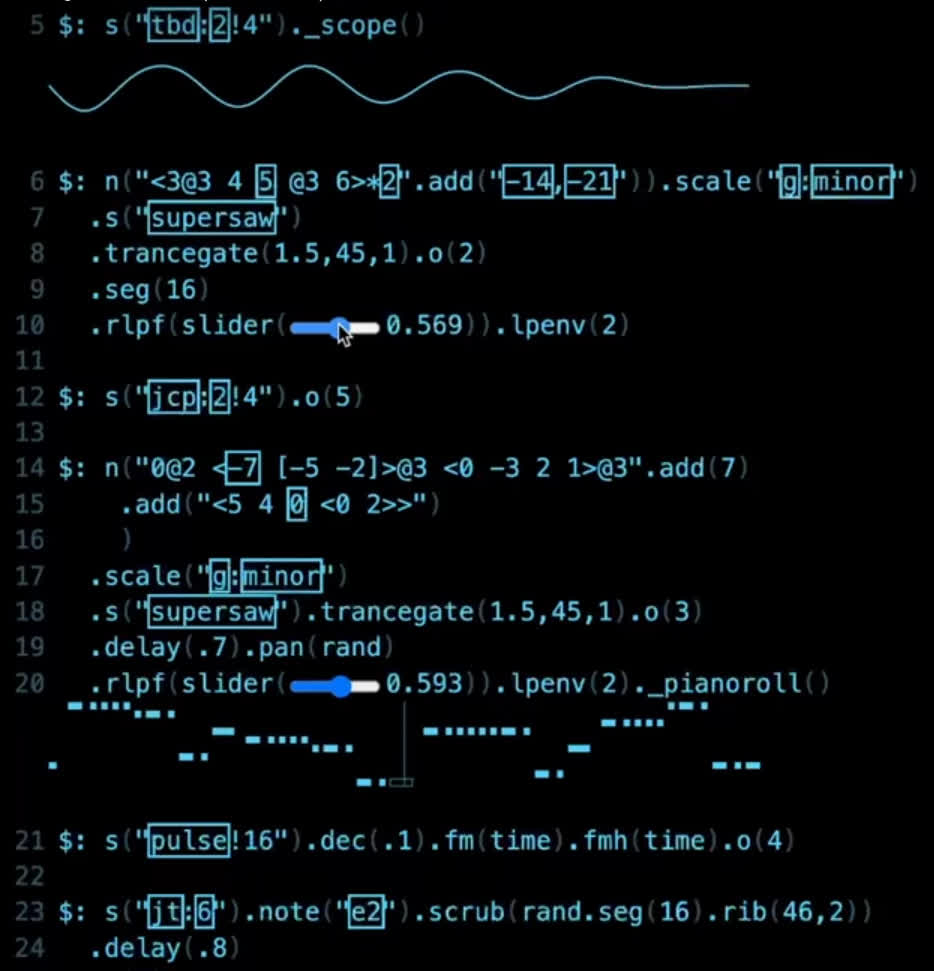
Today I (re)found Strudel, “a JavaScript version of tidalcycles, which is a popular live coding language for music written in Haskell.”
The language and editor are designed as a unified system where the code is the user interface. Above screenshot from this live coding session. The code represents audio nodes running in parallel, with highlight boxes moving through the expressions as they’re executed. Nodes can produce sequences of notes, or control and orchestrate other nodes.
Of particular interest are the inline graphical widgets which appear beside/below certain functions, like scope to visualize wave form, slider for numerical input, and pianoroll to show scrolling stack of notes. These UI elements are created and removed by typing in the code editor. The showcase page has more examples. Showcase 🌀 Strudel
Jade Rose performing with various synths via MIDI, superdirt via OSC and the native strudel superdough engine + vocal parts.
Tying back to earlier in the thread.. InterState (for UI, HTML/SVG/WebGL 3D), Demystified Dynamic Brushes (for visual art and vector graphics), and Strudel (for music) - they’re environments designed to be computational media and software substrates.
A complete and self-sufficient programming system
Persistent code & data store
Direct-manipulation UI on that state
Live programming
Programming & using are on a spectrum, not distinct
Conceptually unified — not a “stack”
A programming language, database, and WYSIWYG document unified together.
..Though stretching the sense of language, database, and document. Sometimes a language is not textual but interacting with diagrams, tables, and forms; a database is the runtime memory of objects; and a document is a drawing, musical composition, or application made of state machines.
The other day I spent an hour trying to get the project running, but the setup is outdated (Grunt, Ruby Sass, older JS libraries) and unstable (errors after standard install and build). It’s typical of a fairly complex web site and software from 10 years ago. The CDN issue was the use of HTTP in the URLs, the services themselves are surprisingly still working (but now require HTTPS). If I’m in the mood for a challenge, I’ll try again because I’m still curious to see it in action.
InterState was an experiment and a sketch of what might be, but wasn’t written as a robust framework or library for practical use. No community of users developed it further, nor was there a clear successor of the ideas explored.
In contrast, I remember during my studies of C and Scheme, I often came across a link to an old website or source code from like 1999, which ran just fine as it is (more or less) to this day as expected.
Such robust longevity is rare on the churning web (but not only, seen plenty of unbuildable legacy projects in many languages). It’s a quality to be admired and yearned for in software, as well as in other technologies like automobiles, electronic appliances, buildings.. What’s built to last mere decades anymore.
It re-emphasizes for me the problem statement in the article that started this thread.
I like how this community questions and challenges the limits of malleability, as it relates to security, ease of customizability versus comprehensivity, user freedom versus lithification of knowledge/experience in a layer of abstraction.. To acknowledge the advantages of a locked-down system.
part of a wider trend in many environments to express designs in general-purpose programming language code rather than configuration languages with less expressive power
So the question is not UI as Code vs Data, but rather UI as Code written in programming languages with a range of expressivity and power. I’d say HTML template languages are slightly above data with limited capabilities. And so is CSS.
I found he has a website (same design since at least 1997, pretty common for old-school academics) and a Publications page.
The problem as I see it is that opacity — the inability to trace results back to causes — is built in to the programming languages and tooling that we have built up in the last decades, and it is only rather anomalous (and widely derided) platforms such as the Web have sufficient malleability built in to mitigate this.
I think you’re right that the web is unusually malleable, which explains tireless efforts by authoritarian governments and companies to undermine its security and privacy, to lock down the freedom and expressivity of the web. The social and cultural context has changed since the early visionary days - cyberspace has been colonized by the same forces as an extension of physical space. Digital ID, Chat Control, Protect EU, Secure Boot. The takeover of Twitter and TikTok, the arrest of Telegram CEO in France. The lock-down of Android against “side loading”, which is what Google calls the ability of users to install and run any software they want on the hardware they own..
The list of examples is too long to even start, how the web embodies the fundamentally political nature of malleable systems. The fact that it still retains some essential freedoms is a testament to its resilient design and the foresight of its creators. And the continuous effort by the community of participants.
“Opacity” is a nice term, and its opposite “transparency”. They fit among other qualities discussed like malleability/lithification, ephemerality/persistence, security/vulnerability, fragility/robustness, immutability, complexity, expressivity/comprehensivity. There’s more, but these terms seem to be lenses through which to evaluate aspects of a software system.
opacity — the inability to trace results back to causes
Its opposite would be:
transparency (or clarity) - the ability to trace results back to causes
Neither are inherently good or bad, since abstractions derive their power from hiding complexity - which is an effective use of opacity. For example, higher-level languages with garbage collection or memory management. They reduce cognitive load by hiding its internal mechanisms, often removing the ability of users to manage it manually but also freeing the user from thinking about it.
And legibility, a term from Seeing Like a State: How Certain Schemes to Improve the Human Condition Have Failed.
The book makes an argument that states seek to force “legibility” on their subjects by homogenizing them and creating standards that simplify pre-existing, natural, diverse social arrangements.
Examples include the introduction of family names, censuses, uniform languages, and standard units of measurement.
It’s a neutral term without implicit judgement, since there are advantages to improving the legibility of an organization’s processes, people, objects, physical environment. But it ties into the value of surveillance to enforce a power structure.
Being illegible can be an advantage, for example a niche language used among a small group, like Pig Latin, meant to be opaque and illegible to outsiders. As I read somewhere, “You can’t catch what you can’t see.”
Turing tarpit. Surprisingly the phrase has not been mentioned yet on the forum, though alluded to in various ways.
A Turing tarpit is any programming language or computer interface that allows for flexibility in function but is difficult to learn and use because it offers little or no support for common tasks.
It applies to languages and user interfaces.
Coined by Alan Perlis in the “Epigrams on Programming” (1982):
Beware of the Turing tar-pit in which everything is possible but nothing of interest is easy.
In any Turing complete language, it is possible to write any computer program, so in a very rigorous sense nearly all programming languages are equally capable. However, having that theoretical ability is not the same as usefulness in practice.
Turing tarpits are characterized by having a simple abstract machine that requires the user to deal with many details in the solution of a problem.
Right.. It’s about the power to make decisions and choices, which becomes a burden when it’s not needed.
O-hoh, semantic distance! A bit long but relevant, quoted below.
Semantic Distance in the Gulfs of Execution and Evaluation
At the highest level of description, a task may be described by the user’s intention: “compose this piece” or “format this paper.” At the lowest level of description, the performance of the task consists of the shuffling of bits inside the machine. Between the interface and the low-level operations of the machine is the system-provided task-support structure that implements the expressions in the interface language.
The situation that Perlis (1982) called the “Turing tar-pit” is one in which the interface language lies near or at the level of bit shuffling of a very simple abstract machine. In this case, the entire burden of spanning the gulf from user intention to bit manipulation is carried by the user. The relationship between the user’s intention and the organization of the instructions given to the machine is distant, complicated, and hard to follow. Where the machine is of minimal complexity, as is the case with the Turing machine example, the wide gulf between user intention and machine instructions must be filled by the user’s extensive planning and translation activities. These activities are difficult and rife with opportunities for error.
Semantic directness requires matching the level of description required by the interface language to the level at which the person thinks of the task. It is always the case that the user must generate some information-processing structure to span the gulf. Semantic distance in the gulf of execution reflects how much of the required structure is provided by the system and how much by the user. The more that the user must provide, the greater the distance to be bridged.
..One way to bridge the gulf between the intentions of the user and the specifications required by the computer is well known: Provide the user with a higher-level language, one that directly expresses frequently encountered structures of problem decomposition. Instead of requiring the complete decomposition of the task to low-level operations, let the task be described in the same language used within the task domain itself.
That makes a lot of sense in the context of what I’ve been learning in this thread. A language or interface is an abstract machine for the user to express their intention as an information-processing structure to achieve their goal - ideally with minimal “bit shuffling” at the machine level. So to use a computer the user must program anyway, whether through code directly or the UI (or API), for which the “program” is the sequence of operations the user performs. The user interface is in a literal sense a live coding environment.
Expressive power as a term in computer science and language theory has an in-depth article.
the expressive power (also called expressivity) of a language is the breadth of ideas that can be represented and communicated in that language. The more expressive a language is, the greater the variety and quantity of ideas it can be used to represent.
The design of languages and formalisms involves a trade-off between expressive power and analyzability. The more a formalism can express, the harder it becomes to understand what instances of the formalism say. Decision problems become harder to answer or completely undecidable.
And a beautiful phrase, semantic spectrum.
The semantic spectrum, sometimes referred to as the ontology spectrum, the smart data continuum, or semantic precision, is in linguistics, a series of increasingly precise or rather semantically expressive definitions for data elements in knowledge representations, especially for machine use.
The cost of expressivity and its consequences.
In computability theory, Rice’s theorem states that all non-trivial semantic properties of programs are undecidable. A semantic property is one about the program’s behavior (for instance, “does the program terminate for all inputs?”), unlike a syntactic property (for instance, “does the program contain an if-then-else statement?”). A non-trivial property is one which is neither true for every program, nor false for every program.
The theorem generalizes the undecidability of the halting problem. It has far-reaching implications on the feasibility of static analysis of programs. It implies that it is impossible, for example, to implement a tool that checks whether any given program is correct, or even executes without error.
Seems like a serious existential problem if a programmer cannot prove that a program is correct and error free. That’s the foundation of the entire edifice of software that runs the world. Is this related to Goedel’s Incompleteness Theorem somehow?
Gödel’s incompleteness theorems are two theorems of mathematical logic that are concerned with the limits of provability in formal axiomatic theories.
The theorems are interpreted as showing that Hilbert’s program to find a complete and consistent set of axioms for all mathematics is impossible.
Seems like a serious existential problem if a mathematician cannot define complete and consistent axioms for all of mathematics. So they proved that their field will never reach the entire truth of the subject of their study. Does this go even deeper, like the nature of knowledge itself, and the ultimate unknowability and illegibility of existence?
The theorems demonstrate that no finite set of axioms and rules can capture all mathematical truths. This suggests that our understanding of reality is inherently incomplete and cannot be reduced to a fixed formal framework.
That sounds logical - but somehow disappointing that we’ll never reach total understanding. A mathematician at the time might have been devastated to hear the news, like someone losing their religion.
Some traditionalist mathematicians continued to resist or downplay their significance. This resistance persisted in some form for decades, especially among those who preferred classical approaches to mathematics.
Yes, I’m somewhat Pythagorean in my worldview - I see numbers and computation as an embodiment of pure ideas that reflect from various angles the perfect and eternal Truth. It’s only our human understanding that is imperfect. Listening to old Johann Bach does it every time, or a little of the Ludwig van.
no finite set of axioms and rules can capture all mathematical truths
So an infinite set of axioms could approach it. Also the incompleteness theorems don’t imply that the totality of mathematics, the entire truth, doesn’t exist or that it’s invalid or imperfect. Only that no finite system of logical rules can express the whole thing, or completely prove it to be true. It also doesn’t mean that there aren’t smaller universes within mathematics where everything is known and proven. We just have to be humble in accepting that the totality is beyond our reach, if it exists at all.
Total correctness - is not what it sounds like.
An algorithm is correct with respect to a specification if it behaves as specified. Partial correctness, requiring that if an answer is returned it will be correct, is distinguished from total correctness, which additionally requires that an answer is eventually returned, i.e. the algorithm terminates.
But following the thread, I find Hoare logic.
Hoare logic is a specific formal system for reasoning rigorously about the correctness of computer programs. .. proposed in 1969 by the British computer scientist and logicianTony Hoare.
Hoare is also the inventor of null.
It was the invention of the null reference in 1965. At that time, I was designing the first comprehensive type system for references in an object oriented language (ALGOL W). My goal was to ensure that all use of references should be absolutely safe, with checking performed automatically by the compiler. But I couldn’t resist the temptation to put in a null reference, simply because it was so easy to implement. This has led to innumerable errors, vulnerabilities, and system crashes, which have probably caused a billion dollars of pain and damage in the last forty years.
I wonder why such a seemingly innocuous and useful concept as a null reference caused so much instability and incorrectness in programs. I’ve heard it called “one of the most significant design mistakes in programming language history”. I’ll leave this tangent for later, it feels like I can gain some understanding by studying what made it a big mistake in retrospect. Funny that in creating null he was seeking “absolute safety” and instead opened a Pandora’s Box of programming troubles for decades.
The central feature of Hoare logic is the Hoare triple. A triple describes how the execution of a piece of code changes the state of the computation.
The original ideas for Hoare logic were seeded by the work of Robert W. Floyd, who had published a similar system for flowcharts.
Flowcharts.. So we meet again. It’s foundational stuff, some classics I’ve read (skimmed) before but now with new eyes and more life experience. Chronologically:
The concern about correctness of computer programs is as old as computers themselves. .. We discuss here two key contributions preceding those of Tony Hoare.
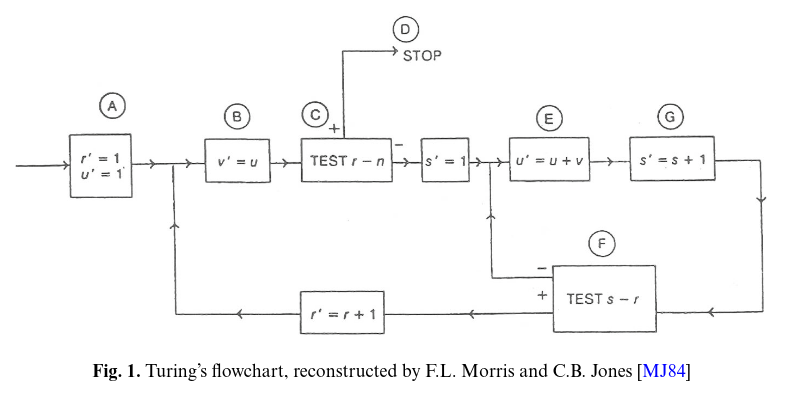
In 1949, Alan Turing gave a presentation entitled “Checking a Large Routine” at a conference in Cambridge U.K. at the occasion of the launching of the computer EDSAC (Electronic Delay Storage Automatic Calculator).
Turing demonstrated his ideas for a flowchart program with nested loops computing the factorial n! of a given natural number n, where multiplication is achieved by repeated addition.
Today, this notation is still in use in logical representations of computation steps like in the specification language Z and bounded model checking.
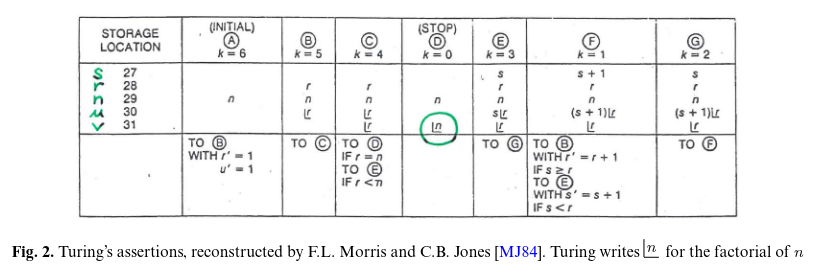
Turing referred already to assertions. In the example he presented them in the form of a table referring to the numbers of the locations storing the variables.
Looks like InterState’s table view that shows all possible states and transitions of a state machine. I’ve also seen node-based graphical programming environments that have a table view of all nodes and their connections.
Robert Floyd was the first to propose a fully formal method for proving the correctness of flowchart programs known as inductive assertions method.
Here the assertions are logical formulas in terms of the variables appearing in the flowcharts. .. To verify that these input-output annotations are correct, each loop of the flowchart needs to be annotated at some selected point with an assertion that should hold whenever the control reaches this point. The assertion should thus be an invariant at this selected point.
While the inductive assertions method is a natural approach to program verification, it is limited to programs that can be represented as flowcharts. This obvious deficiency was overcome by Hoare by proposing an approach that is applicable to programs written in the customary textual form.
Hm, so some programs cannot be represented as flowcharts. I wonder if that’s limited by the notation system, like certain operations are hard/impossible to describe visually. How about some examples of programs that won’t fit in a flowchart..
Infinite loops and recursion
Flowcharts are designed to show sequential processes, but some algorithms involve indefinite repetition
Non-deterministic processes
Concurrent/parallel processing
Flowcharts show one process at a time, while parallel processing involves multiple simultaneous processes
Dynamic data structures
Complex state transitions
Programs with complex state machines that have many possible transitions and conditions. These can involve too many branching paths to be easily represented in a linear flowchart.
Asynchronous operations
Well, if flowchart notation can be considered a kind of language, it means it’s a limited programming language in which certain programs or operations are un-representable.
Right, so flowcharts have limited expressivity. Now I understand, such characteristics can actually be an advantage in limiting the scope, the space of everything a program does and what can be proven correct about it.
What I like about flowcharts (and state tables) is that the entire program and its processes are laid out bare in front of you - nothing is hidden, implicit, or surprising. Feels like if all large programs can be de-composed into such understandable bite-sized units, we might have a chance at building reliable software with robust logic that’s thoroughly verified inside and out.
Yes, there are more such impossibilities barring the road to perfect knowledge. This book chapter is a good summary of some of them, though I am not sure it makes sense without reading a good part of the book first (which is definitely worth reading, but also rather long).
question of where a hypertext document becomes a web application
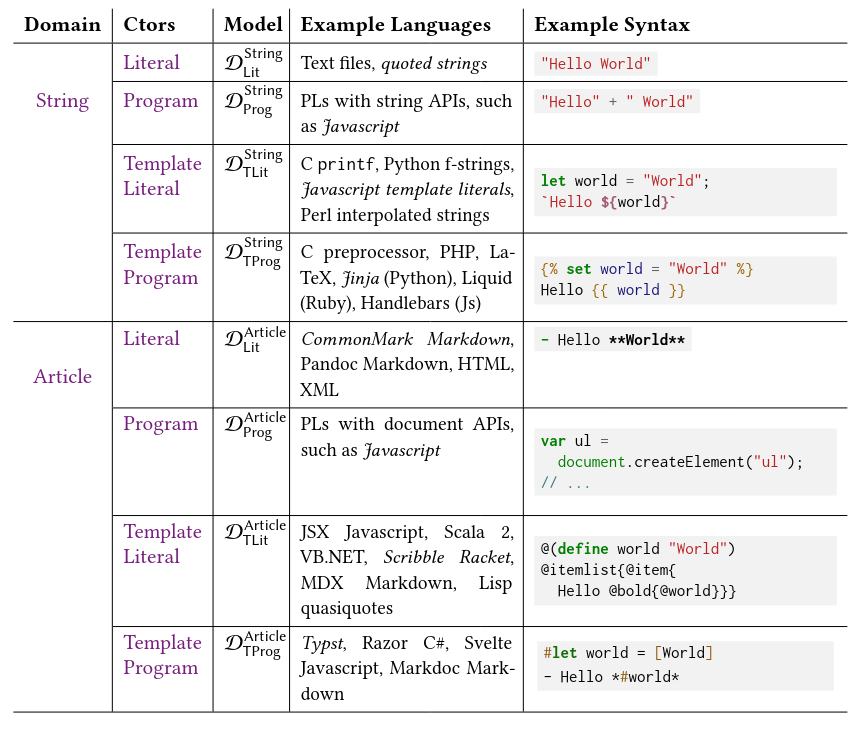
I learned there’s research into a document calculus, related to the “algebra of hypertext” hinted up-thread, an attempt to find unifying principles in markup and template languages.
Passive documents and active programs now widely comingle. Document languages include Turing-complete programming elements, and programming languages include sophisticated document notations. However, there are no formal foundations that model these languages. This matters because the interaction between document and program can be subtle and error-prone.
In this paper we describe several such problems, then taxonomize and formalize document languages as levels of a document calculus. We employ the calculus as a foundation for implementing complex features such as reactivity, as well as for proving theorems about the boundary of content and computation. We intend for the document calculus to provide a theoretical basis for new document languages, and to assist designers in cleaning up the unsavory corners of existing languages.
It’s about dynamic documents that are closer to programs - data that behaves like code - communication that performs computation.
The foundational concept of all document languages is the template. Templates are a kind of generalized data literal. Templates interleave computation (like expressions and variable bindings) into content (like strings and trees).
Modern documents, especially those in the browser, can be reactive to signals such as a timer or user input. Such reactions include animations, interactive widgets, and explorable explanations. Many recently-developed document languages focus on reactivity.
..The widespread adoption of Markdown has demonstrated the strong desire for a concise document syntax. Yet, authors also want computation to simplify authoring of complex documents, as evinced by both the enduring usage of LATEX and the proliferation of “Markdown++” successor languages.
Similar to what’s happening with formats/languages that extend JSON and HTML.
It is an open question how to get the best of both worlds — a human-friendly, concise syntax with a principled, powerful semantics.
..Document languages have long been a subject with a plethora of practice but only tacit theory, especially with regards to the computation/content boundary. Our long-term goal with this work is to provide conceptual clarity to designers of document languages.
I’m interested in something similar regarding Code as UI and warraties to lower cognitive load in order to empower more people via computation. For that, the hypothesis I explored during my PhD is that self-referentiality is one of such warranties, but I arrived at that coming from autopoietic systems (Maturana and Varela) and trying to explore the consequences of it in the co-design and reciprocal modification of grassroots communities and their digital artifacts. My research question was: “How can we change the digital artifacts than change us?” and the approach was to introduce highly self-referential digital artifacts (i.e. those described within themselves instead of external source code and run environments, thus providing live coding capabilities) in grassroots communities and exploring such reciprocal modification. Such research arrived a diffractive genealogy of Convivial Computing, that contrast from the one I have seen from the Global North, where the convivial part is on abstracted users and communities, instead of pretty embodied and concrete ones, as in our case.
My first exploration, Grafoscopio, was made on Pharo and later ported to GToolkit, when the second became available. And now I want to approach that exploration of Convivial Computing, or in other words, the relationship between computing and (inter)personal and community agency with Cardumem.
As with Grafoscopio, with Cardumem I will start with “extended writing”, but this time it will not take the form of a computational notebook and instead will be a minimalist extensible hypermedia wiki engine made in Lua and YueScript, backward compatible with TiddlyWiki data, as we want to bootstrap ourselves from our existing practices there. In that way we can solve TiddlyWiki limitations by creating a tool that complements it and later replaces it (more on that my Community agency and metatools insertion strategies post).
To arrive at end-user programming we need first a tool that is meaningful for us (me and the communities I belong to) in our day to day life. And while I use a computational notebook frequently, I use a wiki engine even more and I have seen people in my communities which use the later (or other PKM tool) but almost never use a computational notebook.
In the context of our minimal wiki engine, we will start with a light markup language and add computational features later, but they will be added with a full computer language with minimal syntax (YueScript).
Code as UI in our case means:
the UI for hypertext writing (via a light markup, probably some extension of Djot)
the UI for changing/extending the wiki behavior and appearance (via YueScript + Mustache).
While still the UI is heavily text based, I foresee that some interesting convivial computing practices can be bootstrapped from such minimal metatool.
Wow! as the one who brought “hypertextual algebra” to the conversation, thanks for the link to Document Calculus.
As I told in my answer to @khinsen now we are going from computational notebooks made in Pharo/GToolkit (with Grafoscopio) to extensible hypermedia wikis made in Lua/YueScript (with Cardumem).
My approach to computational wiki documents this time will use logicless templating in Mustache, so I can keep separated content from programming (eventually, I have thought in using YueScript macros… but it’s just a immature idea, while logicless templating is something that has already given us practical benefits among non-programmers in our communities). YueScript as the extension/programming language for the wiki will be able to read its contents/cards and produce outputs using them and/or their contents as input, in a similar way to TiddlyWiki, but with a more parsimonious extension language (in fact, Cardumem started from imagining such language as a Lua/Fengari extension for TiddlyWiki on a discussion about Tiddlywiki’s pros/cons). For that, YueScript will interface with Lua to access Mustache templating features with a lighter user facing syntax. BTW, I have just browse quickly the document calculus, and so far I can not locate anything related with logicless templating there, maybe because such calculus accounts for how logic is added to the document instead of kept apart by convention (for example the logicless one).
Cardumem is pretty immature now, but it seems like a sound approach. For the reactive part of the document/wiki, I imagine that we will use Server Send Events, that is what is advocated in the hypermedia world for real time hypermedia apps, like Datastar does.









")