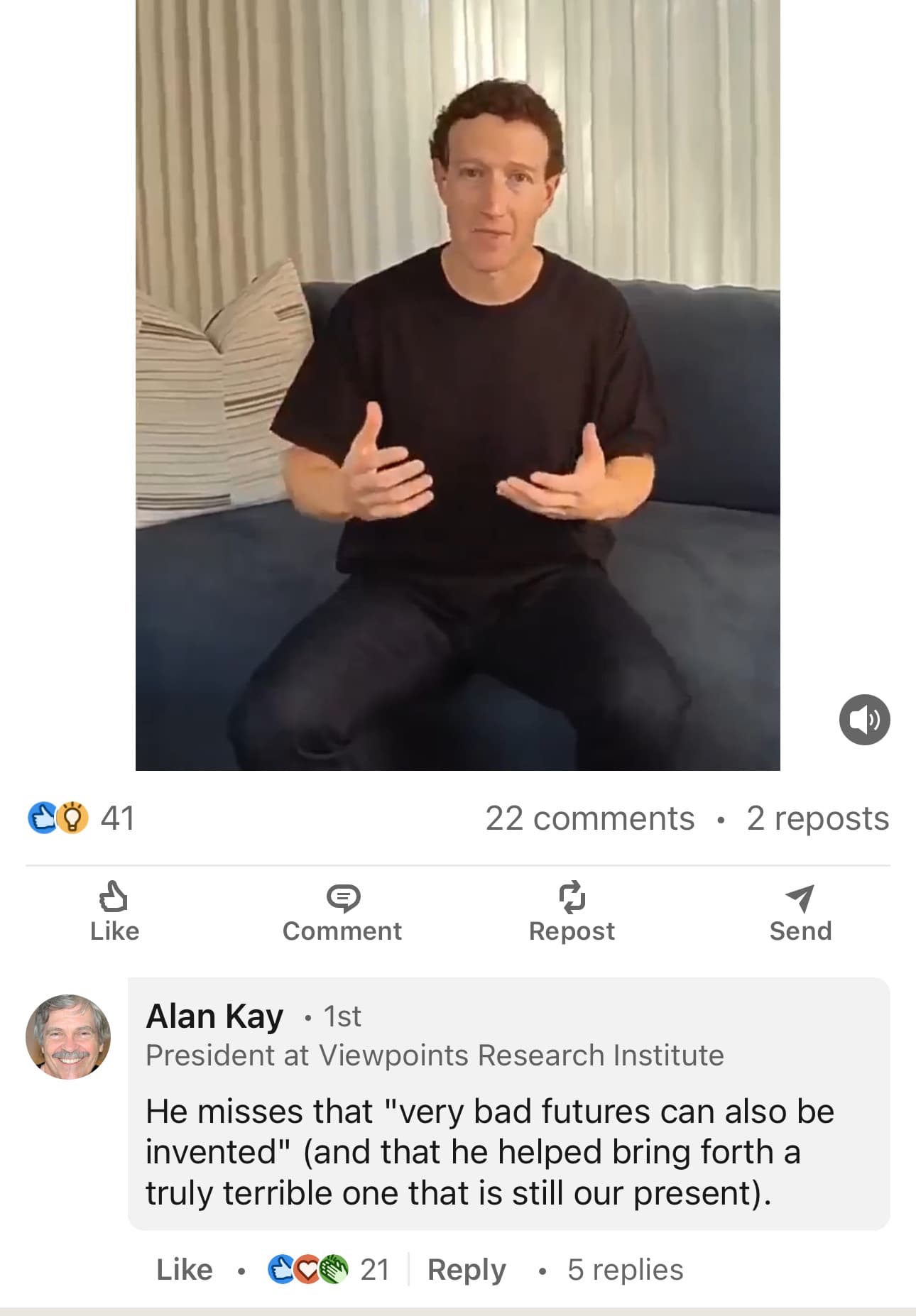
Over the last seven years or so, Alan Kay has been answering questions on Quora ( https://www.quora.com/profile/Alan-Kay-11 ). There’s now a book-length amount of text there from Kay on his philosophy of programming and what he sees as the current big challenges for the Internet and for computer science.
Since Quora is an annoying platform to browse, a few months ago I downloaded all of Kay’s dialogues up to that time and put them on Archive.org as a PDF ( Alan Kay Quora 2023 11 : Free Download, Borrow, and Streaming : Internet Archive )
I’ve been reading through them since (in chronological order - you have to start at the end of the PDF and go backwards, unfortunately), and pondering over the very conflicted feelings I get from Kay. Trying to understand just what his vision of object oriented programming is, and whether I think it’s a good idea or a bad idea, because I’m not really sure.
Here’s an example of that deep sense of philosophical conflcit that I’m chewing on at the moment, from 6 years ago ( https://www.quora.com/If-you-had-to-teach-‘Computer-Science-101’-how-would-you-begin-your-first-lecture ) :
How far and large can we go before things get out of hand and we lose our way in too
much abstraction? I’ve always been partial to the characterization of Alan Perlis — the
first Turing Award winner and who perhaps coined the term “Computer Science” —
who said in the 60s: “Computer Science” is the “science of processes”. All processes. For
Quora, let’s not try to pound this further or make it into religious dogma. Let’s just
happily use Al Perlis’ idea to help us think better about our field. And especially how
we should go about trying to teach it.
…
Another reason for Al Perlis’ choice of definition is because computing in the large is
much more about making systems of many kinds than it is about algorithms, “data
structures”, or even programming per se. For example, a computer is a system,
computations are systems, the Ethernet and Internet are systems, and most programs
should be much better systems than they are (old style programming from the 50s
has lingered on to the point that it seems to many that this is what “programming” is
and should be — and nothing could be farther than the truth).
Okay. So far so good. Alan Kay likes systems more than he likes data structures and algorithms. I get that. As a philosophy, it sounds good. The real world (especially the biological and social world) is made up of systems, not data. Therefore, let’s make everything live, reactive, autonomous. Make everything out of small computers, sealed boxes, exchanging information and control through messages. We started to do this in the 1970s, but we got distracted by early and partial results like the Macintosh, C++, and HTML, so let’s finish the job and build out JCR Licklider’s original ARPA computational utopia. It’s a very romantic, stirring, dream. The Internet’s version of Manifest Destiny.
But!
We now live in an Internet which is an extremely hostile environment. The freedom we once took for granted from the 1990s through 2000s is under attack from multiple angles: from trillions of dollars of speculative venture capital forcing ever more complex and ever more centralized systems. From militaries and governments trying to turn our personal automation into surveillance devices. From weaponised hacking groups, often as part of active shooting wars, trying to deliberately destroy and subvert our automation. From machine learning and generative AI, tools which are fundamentally incapable of being understood even by their creators and are adding vast amounts of opacity and complexity and centralization onto an already frayed social fabric. Because of all this, we now have a massive crisis of trust, and an increasing sense of depression and fear that this already bad situation can now only spiral down into something even worse.
And all of this toxicity and damage - in my opinion - is enabled by the Internet increasingly being about systems and NOT being about algorithms and data structures. Because data structures and algorithms can be stopped and analyzed and checked for safety in ways that live, interactive, always-on systems just can’t be.
This is the conflict I’m feeling right now, reading Alan Kay’s words and trying to parse out his vision. He wants programming to be more about systems, but I’m already afraid that we’ve built too many systems that now have lives of their own and are not under sane human control. And that perhaps the way to win back some small element of control and trust, before it’s too late, can only come from moving away from live systems and back to “dumb” data structures and fully exposed algorithms, completely separated from both data and network.
In other words, I worry that we should not imagine a global network of active closed biological cell-like systems exchanging messages. Rather, we should imagine a global network of dumb data structures that we exchange as data, not as messages. And then local, detached algorithms completely under our control that we apply to those data structures.
This is a very different vision from Kay’s. So I worry that Kay’s unfinished ARPA/PARC vision, exciting as it is, would move us in precisely the wrong direction if anyone were to try to pick it up and implement it.
Here’s another example of Kay’s vision, this time in the words of another old ARPA AI veteran, Carl Hewitt. Hewitt’s words - against the backdrop of the Cloud of 2024 - fill me with a sense of utter bleakness and dread:
Project Liftoff: Universal Intelligent Systems (UIS) by 2030
Universal Intelligent Systems (UIS) will encompass everything manufactured and every sensed activity. Every device used at home and work will be included as well as all equipment used in recreation, entertainment, socializing, and relaxation including clothing, accessories and shoes.
Information will be integrated from massive pervasively inconsistent information from video, Web pages, hologlasses (electronic glasses with holographic-like overlays), online data bases, sensors, articles, human speech and gestures, etc. Information integration will enable an intelligent system to be used by other intelligent systems without having to start over from scratch. Information inference will be robust taking into account multiple sources and perspectives and counterbalancing many interests and perspectives. UIS will largely overcome the current reuse pain point that there is no effective inference for information that is balkanized in applications. An Intelligent System will be educable so that it can interactively adapt in real time (instead of relying exclusively on passively attempting to find correlations among inputs.
An Intelligent System will be self-informative in the sense of knowing its own goals, plans, history, provenance of its information. Also, it will have relevant information about its own capabilities including strengths and weaknesses. When overload or other internal trouble is inferred, an Intelligent System will be able to reach out as appropriate to people and other systems.
Security will be paramount for an Intelligent System so that it is not easy to penetrate or to deceive into taking inappropriate action.
Project Liftoff™ to develop and deploy UIS in this decade stands to be a huge development effort comparable to the Apollo Project. Education will be crucial to the success of Project Liftoff because there is an enormous talent shortage.
US has yet to commence Project Liftoff, but there is a growing consensus that a large effort is required to address issues of universal Integrative Intelligent Systems. China is racing to develop its own indigenous universal secure intelligent systems as rapidly as possible [Liu, 2020, Cheng, Feifel, and Shuia 2019, Xin and Chi-yuk 2018, China State Council 2017, Lewis and Litai 1988. Evan Feigenbaum 2003].
The goal of Project Liftoff is to achieve universal Integrative Secure Intelligent Systems by 2030. Project Liftoff is a development effort comparable to the Apollo Project. Education will be crucial to the success of Project Liftoff because there is an enormous talent shortage.
To which I can only say: good lord, no. Do not build this Project Liftoff thing. Don’t even joke about this. If the USA tries to do this, it will go so, so bad, in so many terrifying ways. In fact, it doesn’t even need to go bad - just from reading this text, I can tell it’s already bad.
Yet “Project Liftoff” is also exactly the old ARPA/PARC vision, which sounds so uplifting. The lost Internet we didn’t build, but could! It sounds so hopeful, so awe-inspiring. And here we are on the threshold of achieving it, and it’s one of the most scary things I can imagine. Because you know these “intelligent systems” will be built by and for the military and billionaires, not by and for people, and their idea of “security” will be about stopping ordinary users from having any effect at all. The result will be cataclysmically bad.
Do any of you feel this deep philosophical conflict in Kay’s ideas too? If so, how should we resolve it?