Thank you for sharing your project. I’m reading through the articles on Substack, and I resonate with many of the ideas. It’s fascinating you’ve decided on the relational model as foundation, not only of the data layer but the entire system. I’m trying to picture what that means, the implications of this approach.
I’m only superficially familiar with the term in relation to SQL and its origin in Codd’s A relational model of data for large shared data banks (1970). Rows, columns, tuples. Projection, selection, joins.
In the 1960s, Codd worked out his theories of data arrangement.. To his disappointment, IBM proved slow to exploit his suggestions until commercial rivals started implementing them. Initially, IBM refused to implement the relational model to preserve revenue from IMS/DB, a hierarchical database the company promoted in the 1970s.
I’m a big fan of the tree structure - for some years developing a tree-based template language and user interface design system; but I understand trees can be expressed as a subset of the relational model. I suppose that’s true of graphs and graph databases? The latter is described as a “post-relational” database model, which suggests that it has unique advantages for certain use cases. I think it helps me understand what the relational model is, by comparing it with other data models that are not relational, or based on different paradigms of relations.
IBM did not use Codd’s own Alpha language but created a non-relational one, SEQUEL. Even so, SEQUEL was so superior to pre-relational systems that in 1979 it was copied by Larry Ellison, based on pre-launch papers presented at conferences of Relational Software Inc, in his Oracle Database.
There was a fork in the road of history, and SQL was chosen. I wonder about this Alpha language, described by Codd in the following paper.
The ALPHA sublanguage is a language for manipulating relations. It possesses the following characteristics:
- The full power of the relational calculus - an applied predicate calculus with tuple variables;
- The capability of specifying any of the operations:
- fetch value or set of values
- change value or set of values
- insert element (i.e., tuple) or set thereof into a relation
- delete element (i.e., tuple) or set thereof from a relation
- declare a relation and its domains for inclusion in the established set of data base relations
- drop a relation from the data base.
- The capability (through RANGE statements) of delimiting the scope of interaction between a user or his program on the one hand and the data base on the other;
- A variable binding capability to permit use in either an interactive or batch environment.
The language is accordingly more than a query or search language. In this author’s opinion the frequent separation of query languages from other aspects of retrieval is usually artificial. The proposed language is intended to be a sublanguage (in a semantic rather than syntactic sense) of the languages used by all terminal users of a shared, formatted data base, except those users who have such narrow needs that their requirements can be more efficiently satisfied by a set of pre-structured (or canned) queries and/or updates.
It is also intended to be a sublanguage of such host programming languages as PL/I, Cobol and Fortran.
Interesting, it was meant to be a domain-specific sublanguage. I imagine some programming languages integrate database operations as part of the language specification, instead of a separate DSL/SQL or standard library.
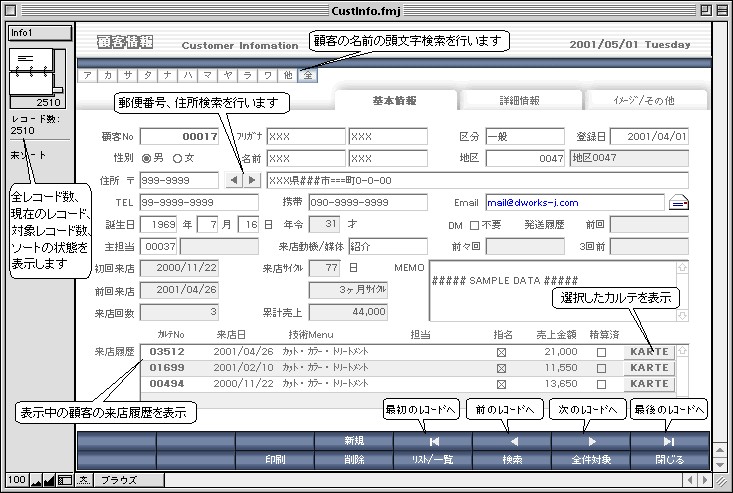
I was curious about this FileMaker mentioned, and found a sweet article written by someone who was inspired by it early in their career as a business application developer.
It wasn’t just a database. It was a development environment that allowed you to design user interfaces intuitively, using drag-and-drop, without needing complex code. You could lay out forms, assign actions, and connect everything to a live database in just a few clicks.
..What made FileMaker even more revolutionary at the time was something called CDML (Claris Dynamic Markup Language). It allowed you to embed database fields directly into HTML-like code, and display or manipulate data in the browser.
But he laments the current state of affairs with “no code” app/UI builders.
The world is filled with no-code tools. .. And yet, none of these modern tools quite match the “satisfaction” I felt with FileMaker. The responsiveness, the seamless integration between UI and logic, the feeling that you’re “actually building something” — that’s still missing..
He still dreams of “a platform that would allow developers and non-developers alike to create fully functional web-based business tools visually and intuitively.”
Could you elaborate on this part, how the relational model can be used to “express” an application? It sounds like the application state/actions/interface is treated as a unified data model.