That’s an interesting and helpful definition of the difference between an “object” (perhaps even a Smalltalk-style object) and an “actor” (a Hewett-style actor and perhaps the Kay-style objects which haven’t been implemented yet even in Smalltalk).
But if an actor is “computing”, it has to be doing so in response to something, though, right? Even if it’s just a long-running computation started by its creation event? But perhaps not doing so just in response to an immediate incoming message?
So would this quality of activeness perhaps be the same as being able to send asynchronous messages rather than the synchronous messages we normally have in Smalltalk and C++ style objects? (Ie: send a message, then continue computing a function/expression/procedure). If so, how exactly do we define the semantics of asynchronous message sends?
Would an asynchronous message send be different from an ordinary synchronous message send that happens to have a “side effect”?
Can have them in anything approaching a functional language (ie a language based on term-rewriting), or are we forced to use an imperative style? (As Hewitt’s actor languages tend to have).
Would asynchronous message sends be anything different from what we do now in C++ and Javascript, where we can send a message that takes an object reference, starts a new thread, does some computation, and at a later time uses that object reference to send a synchronous message to us with the response? If we already have objects that can invoke multiple threads, why is this not enough to be considered Kay objects or Hewitt actors? Is there some specific thread-safety or multiprocess communication locking/blocking/etc property implicit in the Kay/Hewitt vision of exactly how messages are sent, that hasn’t quite been spelled out?
(For instance: Kay really doesn’t seem to like Communicating Serial Processes as a model of multiprocessing at all. I’m not sure yet why, but that feels like it’s probably a key to understanding his specific vision of message-sending.)
In a single thread, could we approximate either “activeness” or asynchronous message sends through the use of coroutines or generators?
Is coroutines/generators in fact what Scheme’s “hairy control structure” (continuations) was all about? I feel like I’ve read somewhere that it was, that Scheme’s big idea was continuations, and that continuations came about because of Hewitt’s proto-Actor ideas in PLANNER inspiring the idea of trying to model communicating processes in a single-threaded Lisp-like language.
If Scheme’s continuations were an attempt to approximate the 1970s ARPA object / actor idea of objects which were really like little servers or processes, continuing to do computations while responding to messages… did continuations in fact succeed at this? There’ve been Web frameworks written using the continuation idea, and they seemed to work well enough?
But would Alan Kay consider Scheme a true implementation of his object ideas? I suspect not, but if not, why not? What would Scheme need to add (or remove) to get there?
Or am I still completely missing the point, and is “activeness” in the sense you understand something completely different from asynchronous message sending?
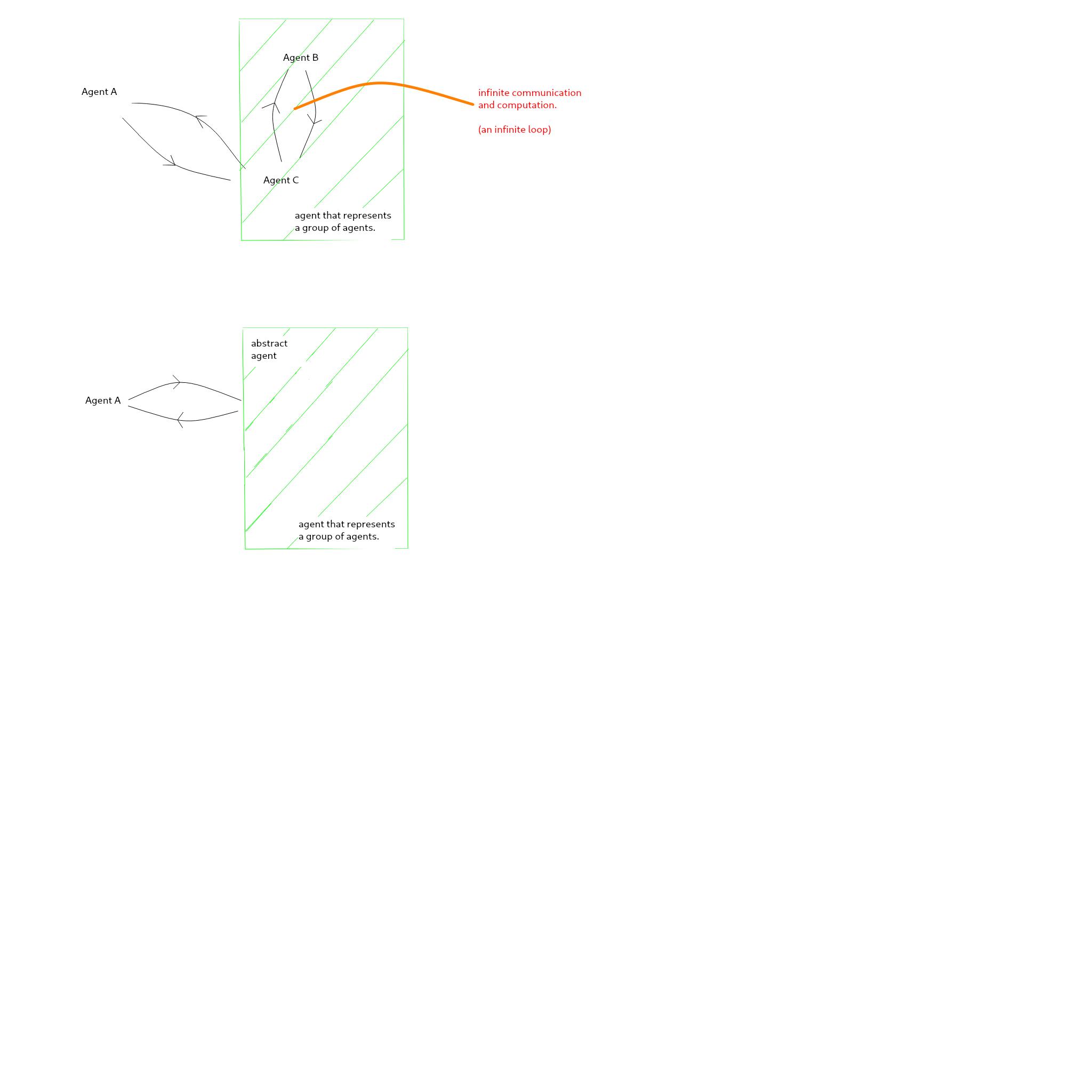
Nothing that I know has managed to describe sets of actors as a single actor. We only have primitive actors.
That’s something that’s worried me for quite a while too (if I understand you correctly).
I want a language where one object can represent (simulate, proxy) a group of objects - and not just a group of objects (because any object can contain references to a group of other objects), but objects physically stored inside that container object, and visible to other objects as references ‘inside’ otherwise really existing objects. So that an object can represent something like a transaction, commit, changeset, container, package, copy-on-write-filesystem, etc - a set of objects that override the “inheritance chain” or however it is other objects locate them. Compositions of such objects would need to be able to be cleanly decomposed too (ie, rollling back a transaction or changeset), and also there should be a way for objects containing other objects in this manner to be stored very close together in storage (to try to avoid defragmentation and cache-smashing).
I’m not sure how to achieve this. I feel like it’s maybe doable just by a hashtable/dictionary with a computed “inheritance” mechanism (maybe Smalltalk’s notUnderstood, or Lua’s metatables could do it?) But maybe it needs some special virtual machine support (particularly for the “objects should be stored physically inside the container object”) bit.
But in smalltalk, an object can be shared among multiple objects. Thus it is impossible to separate the groups of actors into a single abstract entity with a unified behavior, an abstract actor.
Ah! Yes, that (in my idea) might be part of the bit that needs “special VM support”: these “virtual objects” created by the “container object” would need to appear to other objects as having their own individual VM-level object references. And one of the major points of the object model, as I understand it, is that the VM must guarantee that objects cannot fake up object references whenever they wish.
I suppose, in a suitably reflective object system (ie anything with something like “notUnderstood”), the container object could create some tiny “proxy” objects (to create the object references) which then connect back to the container object to get their “actual implementation”. It all seems rather messy though. And also, feels familiar: an instance of the Gang of Four Flyweight Pattern perhaps? But in the kind of system I imagine, “virtual objects and containers” would exist everywhere and be used so much that it would be much, much better for the VM to natively do this if it can.
However, I’m not at all sure if this thing I’m talking about (“container objects / virtual objects”) is the thing you’re referring to, though? If not, can you unpack your “sets of actors as a single actor” idea a bit more?